Table de hachage - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
En informatique, une table de hachage est une structure de données qui permet une association clé-élément, c'est-à-dire une implémentation du type abstrait table de symboles.
On accède à chaque élément de la table via sa clé. Il s'agit d'un tableau ne comportant pas d'ordre (un tableau est indexé par des entiers). L'accès à un élément se fait en transformant la clé en une valeur de hachage (ou simplement hachage) par l'intermédiaire d'une fonction de hachage. Le hachage est un nombre qui permet la localisation des éléments dans le tableau, typiquement le hachage est l'index de l'élément dans le tableau. Une case dans le tableau est appelée alvéole.
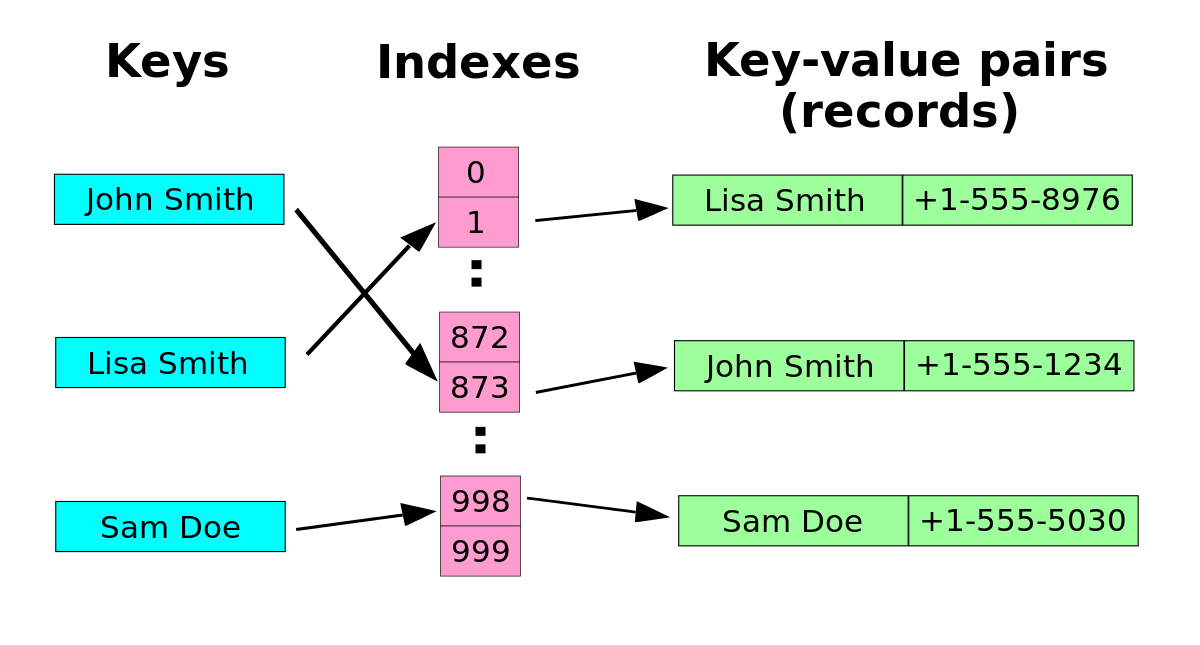
Tout comme les tableaux, les tables de hachage permettent un accès en O(1) en moyenne, quel que soit le nombre d'éléments dans la table. Toutefois le temps d'accès dans le pire des cas peut être de O(n). Comparées aux autres tableaux associatifs, les tables de hachage sont surtout utiles lorsque le nombre d'entrées est très important.
La position des éléments dans une table de hachage est pseudo-aléatoire. Cette structure n'est donc pas adaptée pour accéder à des données triées. Des types de structures de données comme les arbres équilibrés sont généralement plus lents (en O(log n)) et sont plus complexes à implémenter mais maintiennent une structure ordonnée.
Le fait de créer un hash à partir d'une clé peut engendrer un problème de collision, c’est-à-dire qu'à partir de deux clés différentes, la fonction de hachage pourrait renvoyer la même valeur de hash, et donc par conséquent donner accès à la même position dans le "tableau". Pour minimiser les risques de collisions, il faut donc choisir soigneusement sa fonction de hachage.
Choix d'une bonne fonction de hachage
Une bonne fonction de hachage est cruciale pour les performances. Les collisions étant en général résolues par des méthodes de recherche linéaire, une mauvaise fonction de hachage, i.e. produisant beaucoup de collisions, va fortement dégrader la rapidité de la recherche. D'autre part, il est préférable que la fonction de hachage ne soit pas de complexité élevée.
Le calcul du hachage se fait parfois en 2 temps :
- Une fonction de hachage particulière à l'application est utilisée pour produire un nombre entier à partir de la donnée d'origine.
- Ce nombre entier est converti en une position possible de la table, en général en calculant le reste modulo la taille de la table.
Les tailles des tables de hachage sont souvent des nombres premiers, afin d'éviter les problèmes de diviseurs communs, qui créeraient un nombre important de collisions. Une alternative est d'utiliser une puissance de deux, ce qui permet de réaliser l'opération modulo par de simples décalages, et donc de gagner en rapidité.
Un problème fréquent et surprenant est le phénomène de clustering qui désigne le fait que des valeurs de hachage se retrouvent côte à côte dans la table, formant des clusters. Ceci est très pénalisant pour les techniques de résolution des collisions par adressage ouvert. Les fonctions de hachage réalisant une distribution uniforme des hachages sont donc les meilleures, mais sont en pratique difficile à trouver.
Dans les environnements où un adversaire essaye d'attaquer les performances de la recherche en soumettant des entrées générant un grand nombre de collisions afin de ralentir la recherche, une solution est le hashing universel, qui sélectionne aléatoirement une fonction de hachage au début de l'algorithme. L'adversaire n'a alors pas de moyen de connaitre le type de données qui produira des collisions.

















































