Segmentation en plans - Définition
La liste des auteurs de cet article est disponible ici.
Introduction
La segmentation en plans est l'identification automatique, par des méthodes informatiques, des bornes des plans dans une vidéo. Cela consiste à repérer automatiquement les points de montage définis à l'origine par le réalisateur, en mesurant les discontinuités entre les images successives de la vidéo. Ces points de montage sont évidemment connus du réalisateur de la vidéo, mais ne sont généralement pas divulgués, ou disponibles. Afin d'éviter à un opérateur humain un long et fastidieux repérage des plans par visionnage, des méthodes automatiques ont été développées par les chercheurs en informatique.
C'est le problème le plus ancien et le plus étudié en indexation vidéo, considéré comme étant une brique de base indispensable pour permettre l'analyse et la recherche de vidéos. Il n'existe pour l'instant que peu d'applications directes de la segmentation en plans pour le grand public, ou dans des logiciels de vidéo numérique. Toutefois, c'est une étape majeure dans l'analyse de la vidéo, permettant la définition et l'utilisation de techniques de recherche d'information dans des vidéos.
Définition
La segmentation en plans consiste à déterminer les différents plans d'une vidéo. Ceci n'a de sens que si la vidéo contient effectivement des plans, c'est-à-dire qu'elle a été montée par un réalisateur. Certains types de vidéos (vidéo-surveillance, vidéos personnelles...) ne se prêtent donc pas à ce type de technique. Les vidéos généralement considérées sont des films ou des émissions de télévision.
La segmentation en plans est parfois (incorrectement) appelée « segmentation en scènes », par certains chercheurs. La segmentation en scènes est toutefois une tâche différente, qui consiste à identifier les scènes, cette notion étant définie comme un regroupement de plans partageant une certaine cohérence sémantique.
On peut aussi se référer à la segmentation en plans comme à un « inverse Hollywood problem », pour souligner qu'il s'agit de l'opération inverse du montage : c'est la déconstruction de la vidéo afin d'identifier les briques de base filmées par le réalisateur : les plans.
Différents types de transitions entre plans
Il existe de très nombreuses façons de réaliser une transition entre deux plans. La plus simple est la transition brusque : on passe d'un plan à un autre sans image de transition. Pour rendre ce passage plus souple, les réalisateurs ont imaginé une grande variété de transitions progressives, les fondus au noir, les fondus enchaînés, les volets, et bien d'autres, rendues de plus en plus aisées par l'utilisation de l'informatique, et même de logiciels grand public de montage vidéo.
Pour la segmentation en plans, les chercheurs ne distinguent généralement que deux types : les transitions brusques (appelées aussi coupures, de l'anglais « cut »), et les transitions progressives, qui incluent tous les autres types de transitions.
Méthodes
L'idée principale à la base des méthodes de segmentation en plans est que les images au voisinage d'une transition sont fortement dissemblables. On cherche alors à repérer les discontinuités dans le flux vidéo.
Le principe général est d'extraire une observation sur chaque image, et de définir ensuite une distance (ou mesure de similarité) entre observations. L'application de cette distance entre deux images successives, sur l'ensemble du flux vidéo, produit un signal unidimensionnel, dans lequel on cherche alors les pics (resp. creux si mesure de similarité), qui correspondent aux instants de forte dissimilarité.

Observations et distances

L'observation la plus simple est tout simplement l'ensemble des pixels de l'image. Pour 2 images I1 et I2 de dimension N×M, la distance évidente est alors la moyenne des différences absolues pixels à pixels (distance L1):
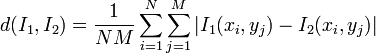
Des approches plus raffinées peuvent ne mesurer que les changements significatifs, en filtrant les pixels qui génèrent des différences trop faibles, qui ne font qu'ajouter du bruit.
Malheureusement, les techniques dans le domaine pixellique sont très sensibles aux mouvements d'objets ou de caméra. Des techniques de bloc matching ont bien été proposées pour réduire la sensibilité au mouvement, mais les méthodes dans le domaine pixellique ont été largement supplantées par les méthodes basées sur les histogrammes.
L'histogramme, de luminance ou de couleur, est une observation très utilisée. Elle est facile à calculer, et est relativement robuste au bruit et aux mouvements d'objets, dû au fait qu'un histogramme ignore les modifications spatiales dans l'image. De très nombreuses techniques de calcul (sur l'image entière, sur des blocs...) et de distances (L1, la similarité cosinus, Test du χ²...) ont été proposées. Une comparaison des performances de différentes observations, sur des contenus vidéo variés, a montré que l'utilisation d'histogrammes produisait des résultats stables et de bonne qualité.
Les méthodes utilisant l'histogramme souffrent toutefois de défauts importants : elles ne sont pas robustes à des changements brutaux d'illumination (flashs de photographes, soleil...), ni à des mouvements rapides.
Afin de résoudre ces problèmes, une autre observation est fréquemment utilisée : les contours de l'image. Ceux-ci sont détectés sur chaque image, grâce à une méthode de détection de contours et, éventuellement après recalage, les contours sont comparés. Cette technique est robuste au mouvement, ainsi qu'aux changements d'illumination. En revanche, la complexité est élevée.
D'autres observations ont été proposées : caractérisation du mouvement de caméra, ou détection dans le domaine compressé à partir des coefficients DCT, ou encore une combinaison d'observations, par exemple intensité et mouvement.
Détection des discontinuités
L'application d'une métrique sur les observations des images successives produit un signal unidimensionnel, dans lequel il faut alors identifier les discontinuités, qui indiquent un changement de plan.
La méthode la plus simple est un seuillage du signal, avec une valeur fixe. Cette méthode souffre de nombreux désavantages : adaptation manuelle du seuil selon le corpus, sensibilité au bruit, au mouvement... Une méthode plus robuste consiste à adapter localement le seuil, en le calculant, par exemple, comme étant la moyenne du signal dans une fenêtre autour du pic considéré.
Une méthode plus satisfaisante est de déterminer la valeur du seuil à partir d'une estimation de la distribution des discontinuités. La distribution est supposée gaussienne de paramètres ![]() et le seuil est défini comme S = μ + rσ, où r est utilisé pour régler le nombre de fausses alarmes.
et le seuil est défini comme S = μ + rσ, où r est utilisé pour régler le nombre de fausses alarmes.
Une approche mieux fondée théoriquement est d'utiliser la théorie de la décision. De façon classique, deux hypothèses sont définies pour chaque image : transition ou non-transition, et la décision est prise en comparant le rapport de vraisemblance au rapport des probabilités a priori. L'emploi d'une méthode d'estimation bayésienne permet de résoudre quelques problèmes liés à cette approche très simple.
Une méthode très différente est élaborée par Truong et al., qui proposent de ne pas prendre une décision locale, mais une décision globale, en essayent de trouver la segmentation optimale sur l'ensemble de la vidéo considérée. Les auteurs adoptent une démarche basée sur le maximum a posteriori, afin de trouver la segmentation qui maximise la probabilité P(S | O), la probabilité que la segmentation S soit optimale, connaissant les observations O. Afin d'éviter une exploration systématique de toutes les segmentations possibles, une technique de programmation dynamique est utilisée.
Améliorations

Les méthodes exposées auparavant ne sont pas toujours efficaces pour détecter les transitions progressives. Heng et al. font remarquer que la plupart des méthodes sont basées sur une mesure de la différence des observations entre images adjacentes, et que ces différences peuvent être faibles pour des transitions progressives.
Pour résoudre ce problème, des techniques basées sur la détection et/ou le suivi d'objets ont été proposées. L'idée générale est que le suivi d'un objet indique une continuité, et que la perte de suivi, peut indiquer une transition. D'autres proposent de modéliser spécifiquement le comportement de chaque type de transition progressive (fondu au noir, fondu enchaîné, volet...) par des méthodes heuristiques et des techniques de double seuillage, ou un réseau de neurones.
Les fondus enchaînés sont particulièrement difficiles à détecter, et certains travaux se concentrent uniquement sur cette tâche. D'autres se concentrent sur les volets, notamment parce que c'est une technique très utilisée à la télévision.
Un autre problème majeur est celui des changements brutaux d'illumination, flashs, spots, apparition/disparition du soleil... Des méthodes spécifiques ont été développées pour diminuer les fausses alarmes liées à ces évènements, en s'aidant de la détection de contours ou d'un post-processing.