SETI@home - Définition
La liste des auteurs de cet article est disponible ici.
Statistiques
Avec plus de 5,2 millions de participants depuis son lancement, ce projet de calcul distribué est celui qui a recueilli le plus de participants jusqu'ici. On est bien au-dessus des intentions initiales, qui visaient l'utilisation de 50 000 à 100 000 ordinateurs personnels. Depuis le 17 mai 1999, le projet a accumulé plus de deux millions d'années de temps d'analyse d'ordinateur.
Avec 1,7 million d'ordinateurs utilisés (4 janvier 2008), SETI@home a une puissance de calcul de 364,8 TeraFLOPS [1]. En comparaison, le superordinateur de 2007, Blue Gene, obtient une vitesse de 478 TeraFLOPS.
Technologie
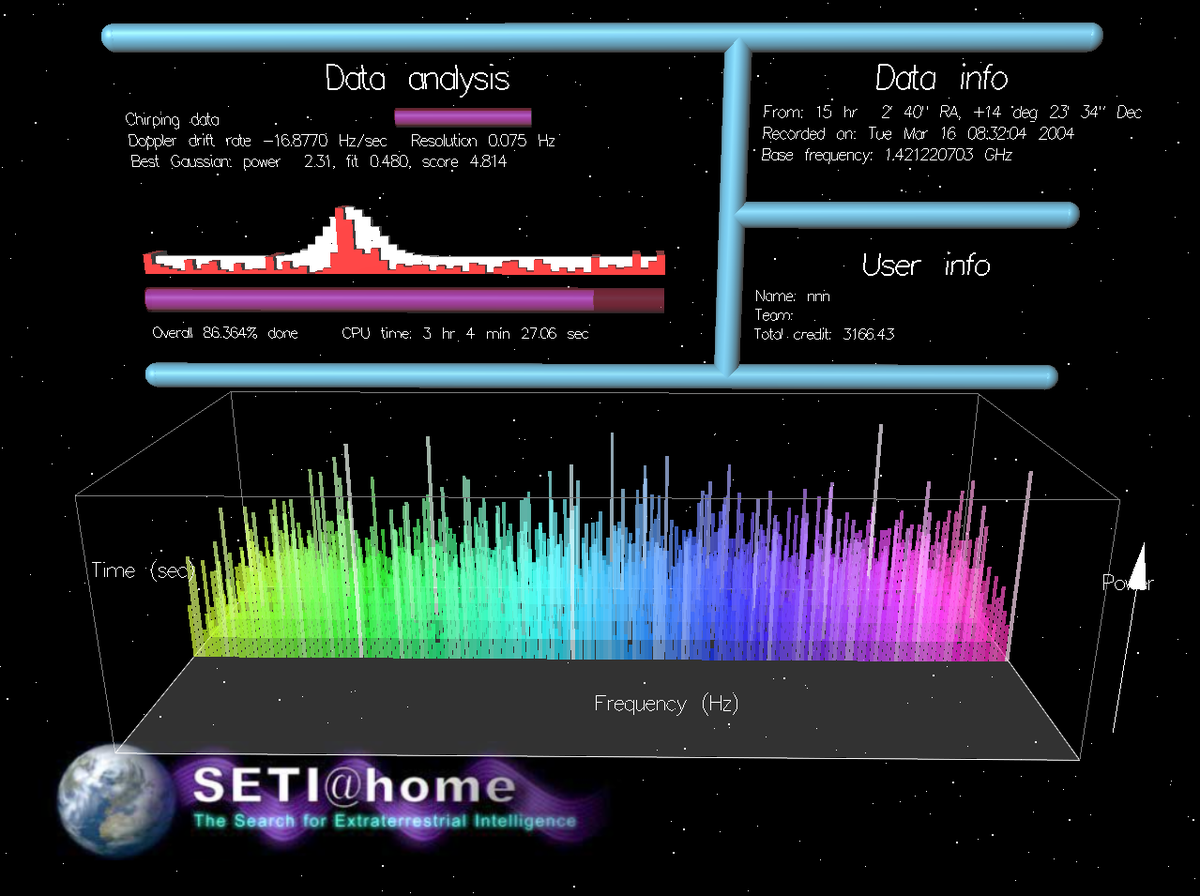
N'importe qui possédant un ordinateur ayant un accès à l'Internet peut participer à SETI@home en exécutant un programme gratuit qui télécharge et analyse les données d'un radiotélescope.
Les données sont enregistrées sur des rubans de 36 Gigabytes à l'Observatoire d'Arecibo, Puerto Rico. Chacun des disques possède 15,5 heures d'observations qui sont par la suite envoyées à Berkeley. Arecibo n'ayant pas de connexion Internet à large bande passante, les données doivent être envoyées par la poste.
Une fois à Berkeley, les données sont divisées en unités de temps et de fréquence de 107 secondes (approximativement 0,35 Megabyte). Ces "unités de travail" (work units) sont alors envoyées partout dans le monde, via l'Internet et à partir du serveur de SETI@home, afin d'être analysées.
Le logiciel d'analyse peut rechercher des signaux ayant le dixième de la force de ceux qui pouvaient être détectés lors d'autres recensements. Ceci s'explique par l'utilisation d'un algorithme informatique puissant nommé coherent integration (que l'on pourrait traduire par intégration cohérente) qui demande une puissance de calcul que nul autre projet SETI n'aurait.
Les unités de travail analysées sont normalement renvoyées automatiquement à Berkeley. Elles y sont stockées dans une banque de données par des ordinateurs dédiés au projet. Les interférences sont éliminées et une panoplie d'algorithmes est utilisée afin de chercher les signaux les plus intéressants.
Logiciel
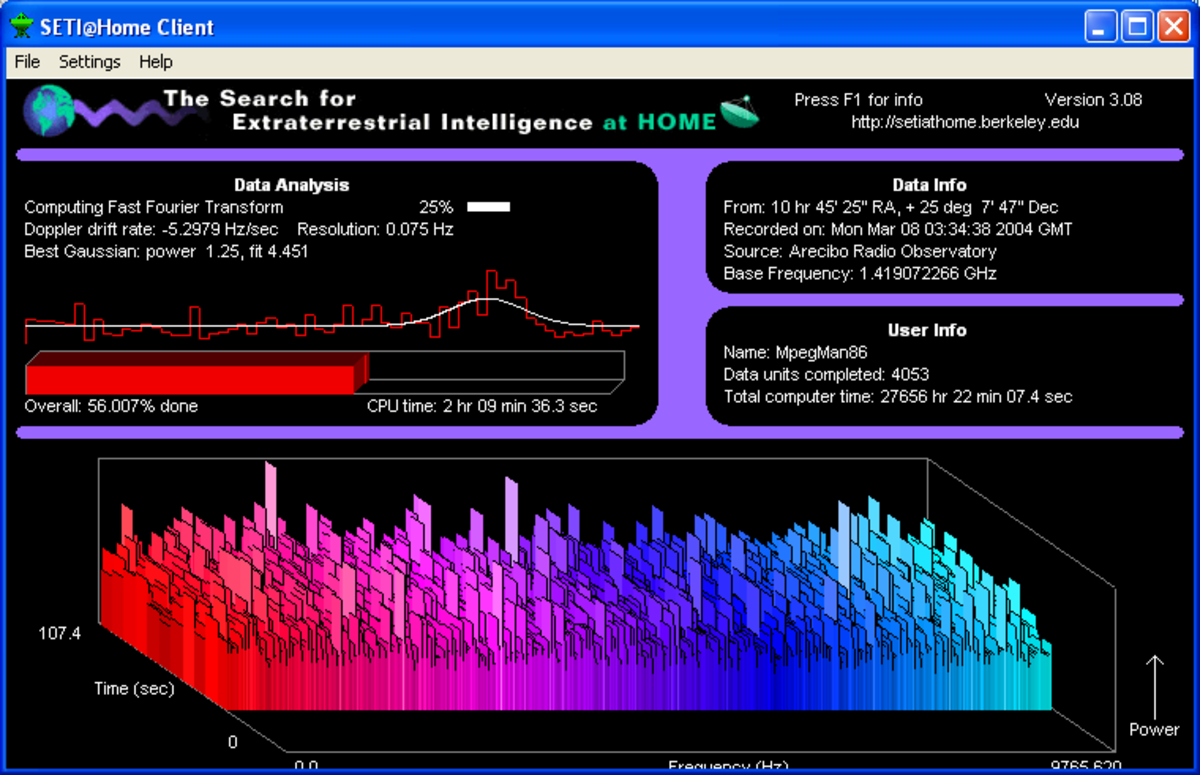
Le logiciel de calcul distribué SETI@home fonctionne soit sous forme d'écran de veille, soit de manière continue pendant que l'utilisateur travaille, utilisant une certaine puissance du processeur qui ne serait pas utilisée autrement.
La plate-forme initiale supportant le logiciel, nommée désormais "SETI@home classique" (SETI@home classic), fut utilisée du 17 mai 1999 au 15 décembre 2005. Elle ne pouvait faire fonctionner que le projet SETI@home. Elle a été remplacée par le Berkeley Open Infrastructure for Network Computing (BOINC, pouvant se traduire par "Infrastructure ouverte de Berkeley pour le calcul distribué ") qui permet aux utilisateurs d'analyser plus de types de signaux et de participer à d'autres projets de calcul distribué en même temps que celui de SETI@home.
La discontinuation du SETI@home classique a empêché les ordinateurs Macintosh utilisant des systèmes d'exploitation pré-OS X de pouvoir participer au projet.
Le 3 mai 2006, de nouvelles unités de travail pour une nouvelle version de SETI@home, appelée "SETI@home Augmenté" (SETI@home Enhanced), ont été distribuées. Ainsi, les ordinateurs fournissent la puissance pour un travail beaucoup plus intensif qu'à l'origine du projet. Cette nouvelle version est deux fois plus sensible au signaux gaussiens ainsi qu'à certains types de signaux modulés que la version originale (BOINC) du logiciel. Elle a été optimisée au point où elle analyse plus rapidement que les versions précédentes certaines unités de travail. Cependant, d'autres unités de travail (les meilleures, scientifiquement parlant) vont demander un temps d'analyse plus long.
Certaines applications de SETI@home, optimisées pour des types particuliers de processeurs, furent accessibles. On y réfère comme étant les « exécutables optimisés » (optimized executables). En 2008, la plupart de ces applications sont optimisées pour les processeurs Intel.
SETI@home a également été utilisé comme outil pour effectuer des tests de performance sur des stations de travail. Plus précisément comme test en stress en utilisant le processeur à puissance maximale pendant une période soutenue. Cela est particulièrement utile pour le surfréquençage.

















































