Parallélisme (informatique) - Définition
La liste des auteurs de cet article est disponible ici.
Les programmes
Les tâches d'un programme parallèle sont habituellement appelés processus et peuvent être de plusieurs types selon le système d'exploitation ou la machine virtuelle. Certains processus sont dit légers, les anglophones utilisent plutôt Thread ce qui peut se traduire par fil. Les threads, plus léger encore, utilisés par certaines architectures sont appelés fibers en anglais, c'est-à-dire fibres en français.
Les synchronisations
Plusieurs défis ont du être relevé par la programmation de système parallèle, par exemple celui de traiter des informations sur des processeurs indépendants, chacun ayant peut d'information sur son voisin, y compris lorsqu'une partie de l'architecture est indisponible. Des langages de programmation concurrente, des interfaces de programmation spécialisées et des algorithmes modèles ont été créés pour faciliter l'écriture de logiciels parallèles et résoudre ces problèmes. La plupart des problèmes de concurrence sont des variantes des problèmes rencontrés dans les modèles appelés producteur-consommateur, lecteur-rédacteur ou Dîner des philosophes. Dans le problème « producteur-consommateur », des processus dit « producteurs » produisent des données qui sont posées dans une file d'attente, une ressource bornée, ces données sont consommés par les processus dit « consommateurs ». Le fait que la ressource soit bornés implique que les producteurs doivent attendre que la file se vide pour pouvoir en produire une nouvelle, et elle implique que le consommateur patiente quand cette liste est vide. Un mécanisme d'avertissement entre les producteurs et les consommateurs peut être mis en place pour assurer un meilleur fonctionnement au système. Dans le modèle « lecteur-rédacteur », spécialisé dans le traitement des flux c'est à dire du filtrages, les débits respectifs de l'un et l'autre peuvent causer, une famine du fait de la lenteur du lecteur, l'obsolescence du fait de la lenteur du rédacteur ou d'une manière plus particulière encore du fait de la mise à jour des données. La principale difficulté du programmeur est d'écrire des algorithmes qui produisent des débits comparables pour les uns et les autres. Enfin, le modèle du « Dîner des philosophes » est le modèle le plus fréquent car les cas où l'échange d'information entre processus peut se faire par simple accès à des données via une zone mémoire partagée sont rares et les données, lorsque cette manière est faire est utilisée, doivent n'avoir soit aucun rapport entre elles soit n'avoir pas besoin d'être mis à jour sans quoi des problèmes de compétition surgissent. Ainsi, plusieurs mécanismes adaptés à des échanges plus polyvalent ont donc été inventés, répondant chacun au mieux à un problème spécifique, comme les tubes anonymes adaptés aux filtrage ou les files d'attente de message permettant de diminuer l'attente active dans le modèle producteur-consommateur.
Le choix du mécanisme d'échange de données dépend aussi de type d'architecture matériel pour lequel le langage, l'interface ou l'algorithme est destiné. Autrement dit, un programme destiné à s'exécuter sur une architecture à mémoire partagée ne serait pas identique à celui destiné à une architecture à mémoire distribuée où sur une architectures mixtes. Les programmes s'exécutant sur les architectures partagées vont peuvent simplement partager des zones mémoires, les systèmes à mémoire distribué vont devoir échanger des messages via un bus ou un réseau. POSIX Threads et OpenMP sont, en 2010, les deux Message Passing Interface, c'est-à-dire les deux librairie spécialisée gérant ce protocoles de passage de messages, les plus utilisés. Ces protocoles ont pour objectif de rendre transparent ces échanges.
Ces problèmes dit de « synchronisation » et même plus généralement ceux de communication inter-processus dont ces derniers dépendent, rendent pratiquement toujours la programmation plus difficile malgré la volonté des programmeurs à produire un code source « Threadsafe ».
En outre, le nombre de techniques à mettre en œuvre pour la gestion des échecs matériels ou logiciels se sont particulièrement développées avec l'avènement des architectures distribuées.
Les modèles de programmation parallèle
Le partage des données
Au sein des ordinateurs parallèles, la mémoire vive peut être soit partagée, soit distribuée. Dans le premières l'échange de donnée est plus simple mis nécessite dans la plupart des cas l'usage de mécanismes logiciels particuliers difficiles à programmer efficacement et un bus mémoire à large bande passante. Le seconds cas la bande passante est moins cruciale autrement dit les répercussions d'un flux important sur la vitesse de traitement globales sont plus faibles, mais nécessite l'appel à un système de transmission des données explicite plus lourd.
Dépendance des données
La connaissance des dépendances entre les données est fondamental dans la mise en œuvre d'algorithmes parallèles. Puisque un calculs qui dépend du résultat d'un calculs préalables doit être exécutée séquentiellement, aucun programme ne peut s'exécuter plus vite que l'exécution de le plus longue des enchainements de calculs, c'est-à-dire que le chemin critique. Un des gains de performance du au parallélisme se trouvent donc dans l'exécution de calculs indépendants et des chemins non-critiques en simultané. Les conditions de Bernstein permette de déterminer lorsque deux parties de programme peuvent êtres exécuter en parallèle. Ceci se formalise ainsi :
Soit Pi et Pj deux fragments de programme. Pour Pi, avec Ii les variables d'entrées et Oi les variables de sorties, et de même façon pour Pj. P i et Pj sont indépendants s'ils satisfont les conditions suivantes :



La violation de la première de ces conditions implique une dépendance des flux, c'est-à-dire le premier fragment ⇔ statement produit un résultat utilisé par le second. La seconde condition est une condition d'« anti-dépendance », le premier fragment écrase (i.e. remplace) une variable utilisée par le second. La dernière condition est une conditions sur les sorties, lorsque les deux fragments écrivent une même données, la valeur finale est celle produit par le fragment exécuter en dernier.
Considérons les fonctions suivantes, qui démontrent plusieurs sortes de dépendances :
|
| L'opération 3 dans Dep (a, b) ne peut pas être exécuté avant (ou même en parallèle avec) l'opération 2, car l'opération 3 utilise un résultat d'exploitation 2. Il viole la condition 1, et introduit ainsi une dépendance de flux. |
|
| Dans cet exemple, il n'y a pas de dépendances entre les instructions, de sorte qu'elles puissent être exécutés en parallèle. |
Les conditions de Bernstein ne permettent pas de gérer l'accès à la mémoire entre différents processus. Pour ce faire il faut utiliser des outils logiciels comme les moniteur, les barrières de synchronisation ou tout autres méthodes de synchronisation.
L'accès aux données

Pour accélérer les traitements effectués par les différentes unités de calcul, il est efficace de multiplier les données, c'est typiquement le cas lors de l'utilisation des caches. Ainsi l'unité de calcul travaille à partir d'une mémoire, spécialisée si possible, qui n'est pas la mémoire partagée par l'ensemble des unités de calculs. Lorsque le programme modifie une donnée dans ce cache, le système doit en fait la modifier dans l'espace commun et répercuter cette modification au sein de tous les caches ou cette donnée est présente. Des mécanismes sont mis en place pour que les données restent cohérentes. Ces mécanismes peuvent être décrit par de complexes modèles d'algèbres de processus et ces derniers peuvent être décrits de plusieurs manières au sein de divers langages formels. Le mécanisme à mémoire transactionnelle logicielle est le plus courant des modèles de cohérence, il emprunte à la théorie des systèmes de gestion de base de données la notion de transactions atomiques et les applique aux accès mémoire.
En outre, certaines ressources ne peuvent être disponible en même temps que pour un nombre restreint de tâche. C'est typiquement le cas pour l'accès en écriture sur un fichier sur disque par exemple. Alors que celui-ci est disponible pour théoriquement un nombre infini en lecture seule, le fichier n'est disponible que pour une seule tache en lecture-écriture, toute lecture par un autre processus est alors proscrite. La réentrance est le nom de la propriété du code lorsque celui ci peut être utilisable simultanément par plusieurs tâches.
Situation de compétition
Les processus ont souvent besoin d'actualiser certaines variables communes sur lesquelles ils travaillent. Les accès à ces variables se font d'une manière indépendante, et ces accès peuvent occasionner des erreurs.
| Thread A | Thread B | Dans l'illustration ci-contre, le résultat d'exécution n'est pas prévisible, du fait que vous ne pouvez savoir quand les Thread A et B s'exécutent, cela dépend en effet de la manière dont les exécutions se chevauchent. Dans l'hypothèse la plus simple ou les thread A et B s'exécutent une fois, l'ordre d'exécution des instructions peut être par exemple : Lire, Lire, Add, Add, Écrire, Écrire ou bien Lire, Add, Écrire, Lire, Add, Écrire. Le résultat dans ces deux hypothèses n'est pas le même puisque au final dans le second cas la variable est augmentée de deux alors qu'elle n'est augmentée que de un dans le premier. |
|---|---|---|
| 1A: Lire variable V | 1B: Lire variable V | |
| 2A: Add 1 à la variable V | 2B: Add 1 à la variable V | |
| 3A: Écrire la variable V | 3B: Écrire la variable V |
Ce phénomène est connu sous le nom de situation de compétition. Pour résoudre ce genre de problème, le système doit permettre au programmeur d'utiliser un verrou d'exclusion mutuelle, c'est-à-dire de pouvoir bloquer, en une seule instruction, tous les processus tentant d'accéder à cette donnée, puis, que les autres processus puissent y accéder lorsque le verrou est libéré. Les tâches attendant la levée du verrou sont « mise en sommeil ». Ces opérations de verrouillage en une instruction sont dites « atomiques », du grec ancien ατομος (atomos), qui signifie « que l'on ne peut diviser ».
| Il existe concrètement plusieurs techniques pour obtenir des verrous et des sections critiques où l'accès aux données est « sécurisé » comme ci-contre mais ce genre de mécanismes est source potentielle de bug informatique. | Thread A | Thread B |
|---|---|---|
| 1A: Verrouiller la variable V | 1B: Verrouiller la variable V | |
| 2A: Lire la variable V | 2B: Lire la variable V | |
| 3A: Add 1 à la variable V | 3B: Add 1 à la variable V | |
| 4A: Écrire la variable V | 4B: Écrire la variable V | |
| 5A: déverrouiller la variable V | 5B: déverrouiller la variable V |
Un fort couplage augmente le risque de bugs, aussi il est recommandé au programmeur de les minimiser. En effet si deux tâches doivent chacune lire et écrire deux variables et qu'elles y accèdent en même temps, cela doit être fait avec précaution. Si la première tâche verrouille la première variable pendant que la seconde tâche verrouille la seconde, alors les deux tâches seront mise en sommeil. Il s'agit là d'un cas d'interblocage, autrement appelé d'« étreinte mortelle » ou « étreinte fatale ».
Certaines méthodes de programmation cherchent à éviter d'utiliser ces verrous, appelées Non-blocking synchronization, elles sont encore plus difficiles à mettre en œuvre et nécessitent la mise en place de structures de données très particulières. La mémoire transactionnelle logicielle en est une.
Efficacité et limites
D'une manière générale, plus le nombre de tâches est élevé dans un programme, plus ce programme passe son temps à effectuer des verrouillages et plus il passe son temps à échanger des messages entre tâche. Autrement lorsque le nombre de tâche augmente trop, la programmation concourante ne permet plus d'augmenter la vitesse d'exécution du programme ou plus précisément de diminuer la durée de son chemin critique car le programme passe son temps à mettre en sommeil les taches qui le composent et à écrire des informations qui permettent l'échange d'information entre tâches. Ce phénomène est appelé le parallel slowdown ⇔ ralentissement parallèle.
D'ailleurs les applications sont souvent classées en fonction la fréquence à laquelle ses tâches dialoguent ou se synchronisent. Les applications ayant beaucoup d'échanges ou de synchronisations entre ses sous-tâches sont dite fine-grained à grain fin, celle qui ont au contraire peu d'échanges et de synchronisations sont dite coarse-grained c'est-à-dire à gros grain. L'algorithme est dit Embarrassingly parallel, c'est-à-dire de « parallélisme embarrassant » s'il n'y a aucun contact entre les sous-tâches. Ce dernier est le plus simple à programmer.
Algorithmiques
Les programmes aujourd'hui, sauf exception, sont écrits ou compilés de manière à ce que l'adressage interne soit relatif, c'est à dire que un ensemble d'instruction peu s'exécuter convenablement quel que soit l'emplacement mémoire ou il est stocké. Le code peut donc être dupliqué. L'exécution de multiple code identique ne pose donc aucun problème.
En revanche, si certains problèmes sont simplement divisible en multiple sous-problèmes exécutable par différents processus ce n'est pas le cas de tous les problèmes. Par exemple, s'il est simple de paralléliser la recherche de la liste des nombres premiers et attribuant à chaque processeur une liste de nombre et de regrouper les résultats à la fin. Il est plus difficile de le faire par exemple pour le calcul de π puisque les algorithmes habituels, bâtis sur le calcul de séries, évaluent cette valeurs par approximation de plus en plus précise à partir du résultat précédent. Le calcul des séries, les méthodes itératives, comme la méthode de Newton et le problème des trois corps, les algorithmes récursifs comme celui de l'algorithme de parcours en profondeur des graphes sont par conséquent très difficiles à paralléliser.
Problématique des boucles
Outre la problématique liée à l'accès aux variables comme la concurrence où la réentrance, pour des raisons de performances, les compilateurs doivent prendre en compte la mise en cache de la séquence d'instruction à exécuter lorsqu'il contient des boucles. A chaque exécution d'un saut le cache qui contient les instructions doit être vidé et et de nouveau rempli. Cette action est lente, les compilateurs vont donc chercher à minimiser cet impact.
Problématique sériel ou temporel
Lors de calcul de fonctions récursives, une dépendance est créée au sein d'une boucle, l'exécution de celle-ci ne peut s'effectuer que lorsque la précédente s'est effectuée. Ceci rend le parallélisme impossible. Le calcul de la suite de Fibonacci en est un cas d'école, comme l'illustre le pseudo-code suivant :
1: PREV1:= 0 2: PREV2:= 1 4: do: 5: CUR:= PREV1 + PREV2 6: PREV1:= PREV2 7: PREV2:= CUR 8: while (CUR < 10)
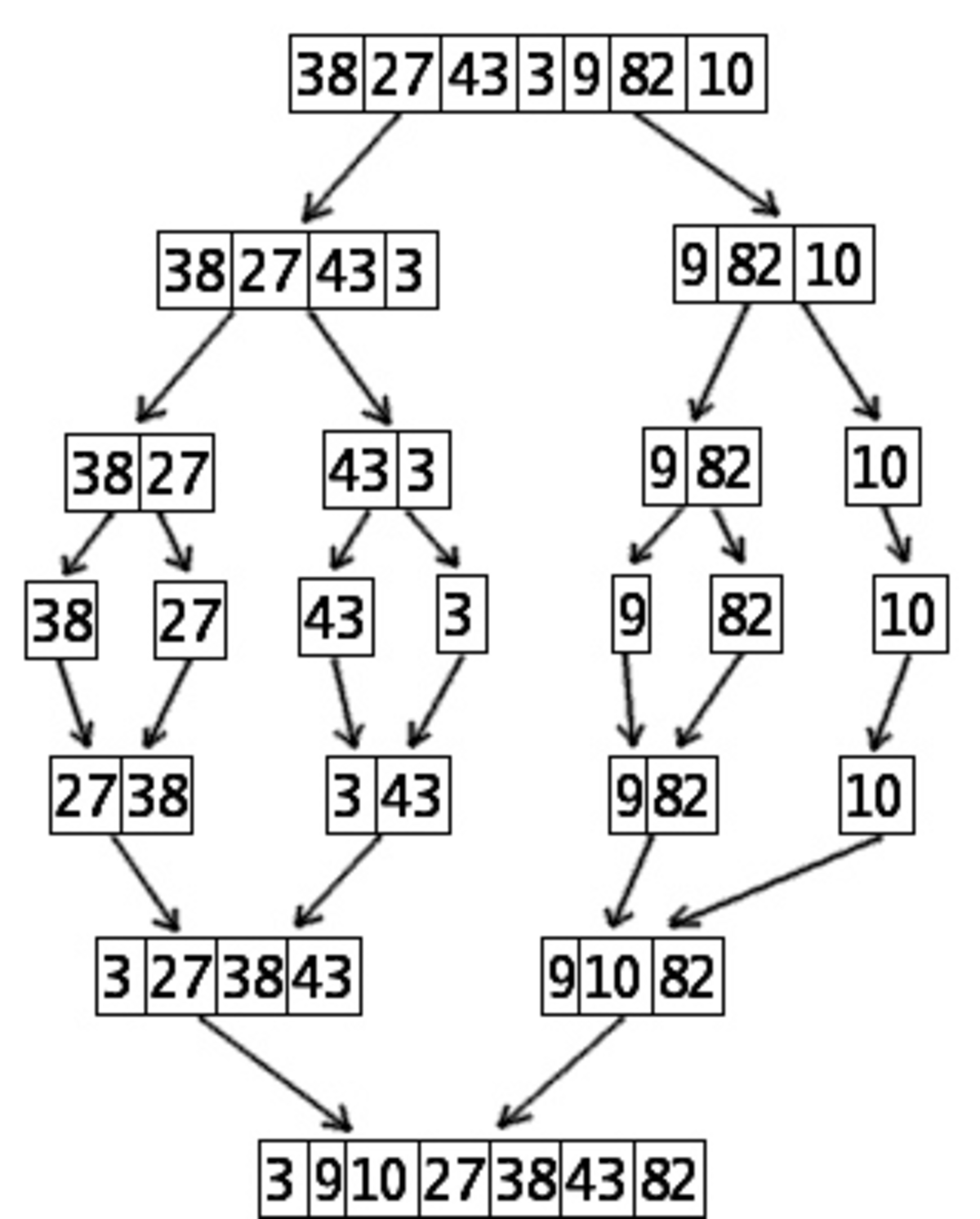
Ce n'est cependant pas cas de tous les algorithmes récursifs, lorsque chaque fonction a un traitement suffisant à effectuer, ils peuvent même être plus efficace que des algorithmes composés de boucle en raison de leur nature : « diviser pour régner ». C'est par exemple le cas pour deux algorithmes de tri récursifs, le Tri rapide et plus particulièrement le Tri fusion. En outre ces deux algorithmes ne créent pas de situation de compétition et il n'est donc pas nécessaire de synchroniser les données.
Si l'algorithme permet de créer une liste de n taches par p processeurs en un temps moyen


Les patrons de conceptions de synchronisation
Barrière de synchronisation • Futex • Moniteur • Mutex • Sémaphore • Spinlock • Algorithme de Peterson • Algorithme de Dekker • Algorithme du banquier
Problématiques logicielles
Le modèle de passage de messages est un modèle de communication entre ordinateurs. Il ne sert pas que pour le calcul parallèle, comme c'est le cas pour les JavaBeans.
- Un des concept utilisé dans la programmation concurrente est le concept de en:Futures and promises ⇔ , une tache promet à une autre qu'elle délivrera la donnée fournie.
- Influence des compilateurs. Cf Explicitly Parallel Instruction Computing, parallélisation automatique

















































