Mémoire cache - Définition
La liste des auteurs de cet article est disponible ici.
Mémoire cache des microprocesseurs
Elle est très rapide, mais aussi très chère. Il s'agit souvent de SRAM.

La présence de mémoire cache permet d'accélérer l'exécution d'un programme. De ce fait, plus la taille de la mémoire cache est grande, plus la taille des programmes accélérés peut être élevée. C'est ainsi un élément souvent utilisé par les constructeurs pour faire varier les performances d'un produit sans changer d'autres matériels. Par exemple, pour les microprocesseurs, on trouve des séries bridées (avec une taille de mémoire cache volontairement réduite), tels que les Duron chez AMD ou Celeron chez Intel, et des séries haut de gamme avec une grande mémoire cache comme les processeurs Opteron chez AMD, ou Pentium 4EE chez Intel. Autrement dit, la taille de la mémoire cache résulte d'un compromis coût/performance.
En programmation, pour profiter de l'accélération fournie par cette mémoire très rapide, il faut que les parties de programme tiennent le plus possible dans cette mémoire cache. Comme elle varie suivant les processeurs, ce rôle d'optimisation est souvent dédié au compilateur. Cela dit, un programmeur chevronné peut écrire son code d'une manière qui optimise l'utilisation du cache.
C'est le cas des boucles très courtes qui tiennent entièrement dans les caches de données et d'instruction, par exemple le calcul suivant (écrit en langage C) :
long i; double s; s=0; for (i = 1; i<50000000; i++) s+=1./i;
Définitions
Une ligne est le plus petit élément de données qui peut être transféré entre la mémoire cache et la mémoire de niveau supérieur.
Un mot est le plus petit élément de données qui peut être transféré entre le processeur et la mémoire cache.
Différents types de défauts de cache (miss)
Il existe trois types de défauts de cache en système monoprocesseur et quatre dans les environnements multiprocesseurs. Il s'agit de :
- les défauts de cache obligatoires : ils correspondent à la première demande du processeur pour une donnée/instruction spécifique et ne peuvent être évités ;
- les défauts de cache capacitifs : l'ensemble des données nécessaires au programme excèdent la taille du cache, qui ne peut donc pas contenir toutes les données nécessaires ;
- les défauts de cache conflictuels : deux adresses distinctes de la mémoire de niveau supérieur sont enregistrées au même endroit dans le cache et s'évincent mutuellement, créant ainsi des défauts de cache ;
- les défauts de cohérence : ils sont dus à l'invalidation de lignes de la mémoire cache afin de conserver la cohérence entre les différents caches des processeurs d'un système multi-processeurs.
Le mapping (ou correspondance)
La mémoire cache ne pouvant contenir toute la mémoire principale, il faut définir une méthode indiquant à quelle adresse de la mémoire cache doit être écrite une ligne de la mémoire principale. Cette méthode s'appelle le mapping. Il existe trois types de mapping répandus dans les caches aujourd'hui :
- les mémoires caches complètement associatives (fully associative cache) ;
- les mémoires caches N-associatives (N-way set associative cache) ;
- les mémoires caches directes (direct mapped cache).
Fully associative cache
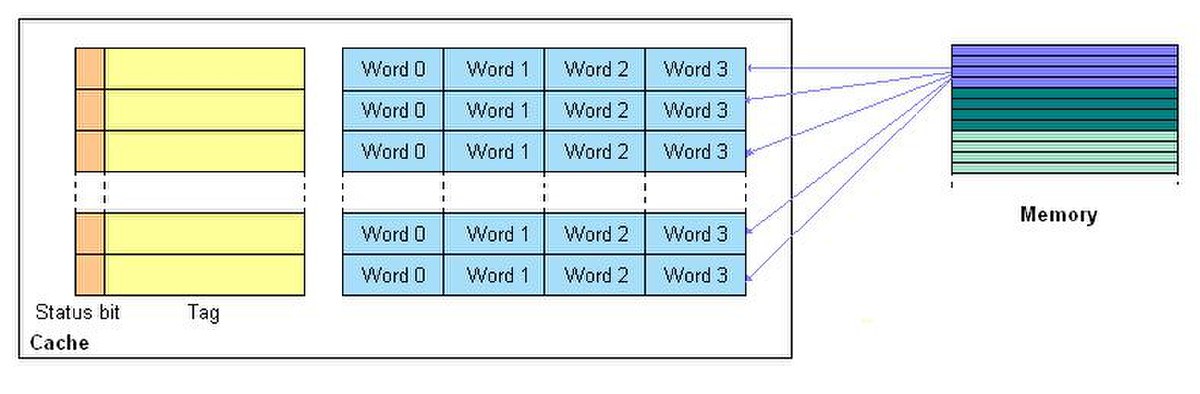
Chaque ligne de la mémoire de niveau supérieur peut être écrite à n'importe quelle adresse de la mémoire cache. Cette méthode requiert beaucoup de logique car elle donne accès à de nombreuses possibilités. Ceci explique pourquoi l'associativité complète n'est utilisée que dans les mémoires cache de petite taille (typiquement de l'ordre de quelques kibioctets). Cela donne le découpage suivant de l'adresse :

Direct mapped cache (cache à correspondance directe)
Chaque ligne de la mémoire principale ne peut être enregistrée qu'à une seule adresse de la mémoire cache. Ceci crée de nombreux défauts de cache conflictuels si le programme accède à des données qui sont mappées sur les mêmes adresses de la mémoire cache. La sélection de la ligne où la donnée sera enregistrée est habituellement obtenue par: Ligne = Adresse mod Nombre de lignes.

Une ligne de cache est partagée par de nombreuses adresses de la mémoire de niveau supérieur. Il nous faut donc un moyen de savoir quelle donnée est actuellement dans le cache. Cette information est donnée par le tag, qui est une information supplémentaire stockée dans le cache. L'index correspond à la ligne où est enregistrée la donnée. En outre, le contrôleur de la mémoire cache doit savoir si une adresse donnée contient une donnée ou non. Un bit additionnel (appelé bit de validité) est chargé de cette information.
Prenons l'exemple d'une adresse de 32 bits donnant accès à une mémoire adressable par octet, d'une taille de ligne de 256 bits et d'une mémoire cache de 2s kibioctets. La mémoire cache contient donc 2s + 13 bits. Sachant qu'une ligne est de 256 bits, nous déduisons qu'il y a 2s + 5 lignes stockables en mémoire cache. Par conséquent, l'index est de s+5 bits.
L'adresse de 32 bits permet d'accéder à une mémoire de 232 octets, soit 235 bits. L'index étant de s+5 bits, il faut distinguer 222 − s éléments de la mémoire principale par ligne de cache. Le tag est donc de 22-s bits.
De plus, une ligne a une taille de 256 bits soit 32 octets. La mémoire étant adressable par octet, cela implique un offset de 5 bits. L'offset est le décalage à l'intérieur d'une ligne pour accéder à un octet particulier. Ces calculs donnent le découpage de l'adresse suivant pour une mémoire cache mappée directement :

Le mapping direct est une stratégie simple mais peu efficace car elle crée de nombreux défauts de cache conflictuels. Une solution est de permettre à une adresse de la mémoire principale d'être enregistrée à un nombre limité d'adresses de la mémoire cache. Cette solution est présentée dans la section suivante.
N-way set associative cache
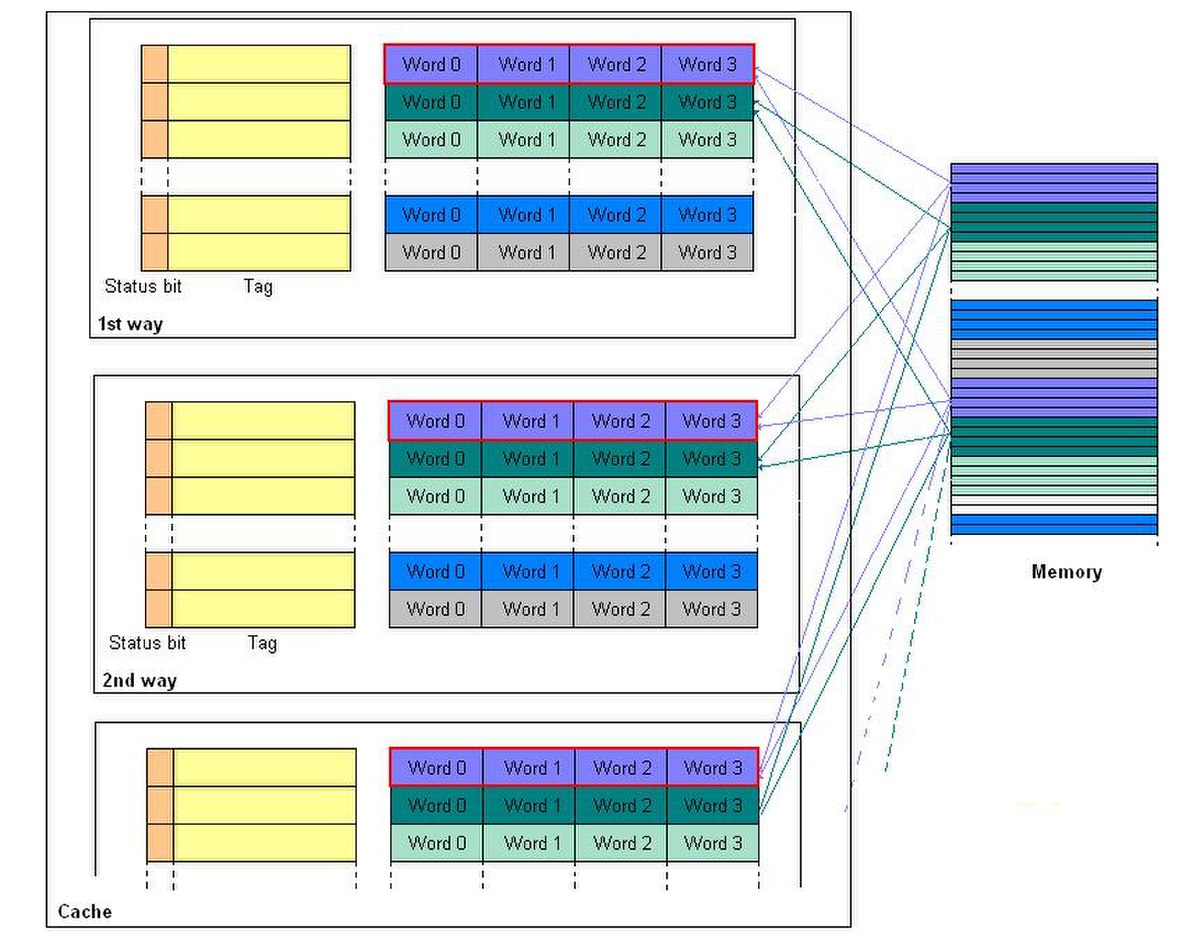
Il s'agit d'un compromis entre le mapping direct et complètement associatif essayant d'allier la simplicité de l'un et l'efficacité de l'autre.
La mémoire cache est divisée en ensembles (sets) de N lignes de cache. Un ensemble est représenté sur la figure ci-jointe par l'union des rectangles rouges. Une ligne de la mémoire de niveau supérieur est affectée à un ensemble, elle peut par conséquent être écrite dans n'importe laquelle des voies. Ceci permet d'éviter de nombreux défauts de cache conflictuels. À l'intérieur d'un ensemble, le mapping est Direct Mapped, alors que le mapping des N Sets est Full Associative. En général, la sélection de l'ensemble est effectuée par : Ensemble = Adresse mémoire mod (Nombre d'ensembles).
Reprenons l'exemple de la section précédente (mémoire cache de 2s kibioctets) mais constitué de 2n voies. Le nombre de voies est en effet toujours une puissance de 2 afin d'obtenir un découpage simple de l'adresse mémoire. La mémoire cache contient donc 2s + 13 − n bits par voie. Sachant qu'une ligne représente 256 bits, il y a donc 2s + 5 − n lignes par ensemble. L'index est donc de s-n+5 bits.
Les mémoires considérées ici sont adressables par octet. Par conséquent, les adresses de 32 bits donnent accès à une mémoire de 235 bits, soit l'équivalent de 227 lignes de mémoire cache. Ainsi, chaque ensemble de la mémoire cache contient 222 − s + n lignes distinctes. Le tag est donc de 22-s+n bits. Le découpage de l'adresse est alors :

Caches unifiés ou caches séparés
Pour fonctionner, un processeur a besoin de données et d'instructions. Il existe donc deux solutions pour l'implémentation des mémoires cache :
- le cache unifié : données et instructions sont enregistrées dans la même mémoire cache ;
- les caches séparés de données et d'instructions.
Séparer données et instructions permet notamment d'augmenter la fréquence de fonctionnement du processeur, qui peut ainsi accéder simultanément à une donnée et une instruction. Cette situation est particulièrement courante pour des Load/Store. Ceci explique que le cache unifié est souvent le maillon faible du système. De plus, dans un cache unifié, une logique supplémentaire donnant la priorité aux données ou aux instructions doit être introduite, ce qui n'est pas le cas pour les caches séparés.
Néanmoins, les caches séparés introduisent un problème de cohérence du cache d'instructions pour les programmes auto-modifiant : quand un programme modifie son propre code en mémoire (RAM), il doit absolument invalider les entrées correspondantes dans le cache d'instruction, afin de provoquer leur mise à jour avant d'exécuter les instructions modifiées, sans quoi une version précédente de ces instructions pourrait être prise en compte et exécuté par le processeur (voire un mélange imprévisible des nouvelles instructions et des anciennes).
De nos jours, la solution la plus répandue est la séparation des caches car elle permet entre autres d'appliquer des optimisations spécifiques à chaque cache, les particularités de comportement des instructions et des données étant très différentes.
Politique d'écriture dans la mémoire de niveau supérieur
Quand une donnée se situe dans le cache, le système en possède deux copies : une dans la mémoire de niveau supérieur (disons la mémoire principale) et une dans la mémoire cache. Quand la donnée est modifiée localement, plusieurs politiques de mise à jour existent :
- write-through : la donnée est écrite à la fois dans le cache et dans la mémoire principale. La mémoire principale et le cache ont à tout moment une valeur identique, simplifiant ainsi de nombreux protocoles de cohérence ;
- write-back : l'information n'est écrite dans la mémoire principale que lorsque la ligne disparaît du cache (invalidée par d'autres processeurs, évincée pour écrire une autre ligne...). Cette technique est la plus répandue car elle permet d'éviter de nombreuses écritures mémoires inutiles. Pour ne pas avoir à écrire des informations qui n'ont pas été modifiées (et ainsi éviter d'encombrer inutilement le bus), chaque ligne de la mémoire cache est pourvue d'un bit dirty. Lorsque la ligne est modifiée dans le cache, ce bit est positionné à 1, indiquant qu'il faudra réécrire la donnée dans la mémoire principale.
Algorithmes de remplacement des lignes de cache
Les caches associatifs de N voies et complètement associatifs impliquent le mapping de différentes lignes de la mémoire de niveau supérieur sur le même set. Ainsi, lorsque le set de lignes de la mémoire cache, où une ligne de la mémoire supérieure peut être mappée, est rempli, il faut désigner la ligne qui sera effacée au profit de la ligne nouvellement écrite. Le but de l'algorithme de remplacement des lignes de cache est de choisir cette ligne de manière optimale. Ces algorithmes doivent être implémentés en hardware pour les mémoires caches de bas niveau afin d'être les plus rapides possible et de ne pas ralentir le processeur. Cependant, ils peuvent être implémentés en software pour des caches de niveau supérieur.
La majorité des algorithmes reposent sur le principe de localité pour tenter de prévoir le futur à partir du passé. Certains des algorithmes de remplacement des lignes de mémoire cache les plus répandus sont :
- aléatoire pour la simplicité de la création de l'algorithme ;
- FIFO(First In First Out) pour sa simplicité de conception ;
- LRU (Least Recently Used) qui mémorise la liste des derniers éléments accédés...

















































