Compilateur - Définition
La liste des auteurs de cet article est disponible ici.
Compilateur simple passe et multi passe
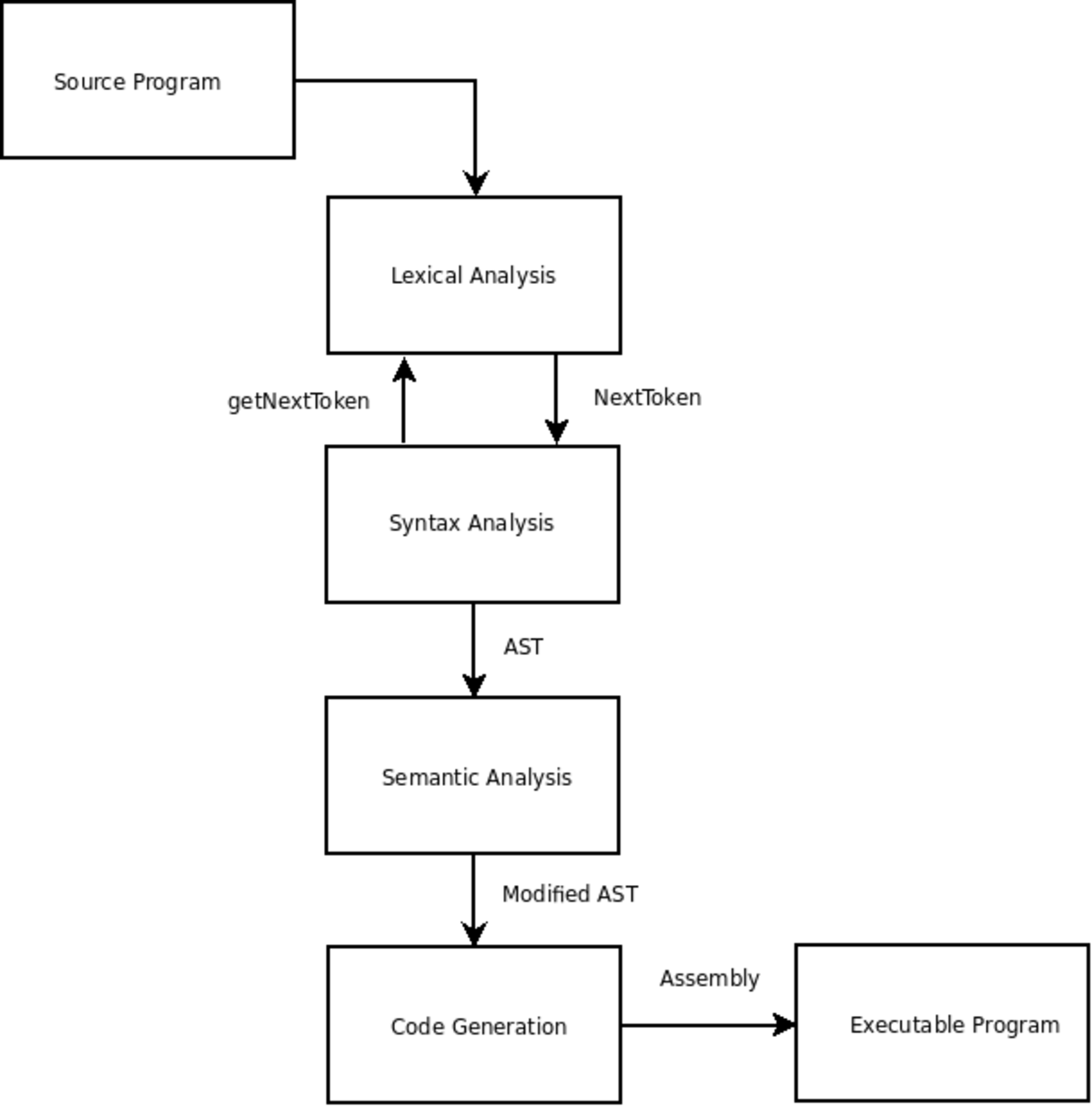
La classification des compilateurs par nombre de passes a pour origine le manque de ressources matérielles des ordinateurs. La compilation est un processus couteux et les premiers ordinateurs n'avaient pas assez de mémoire pour contenir un programme qui devait faire ce travail. Les compilateurs ont donc été divisés en sous programmes qui font chacun une passe sur la source (d’une forme ou d’une autre) pour accomplir les différentes phases d’analyse lexicale, d'analyse syntaxique et d'analyse sémantique.
La capacité de combiner le tout en un seul passage a été considérée comme un avantage car elle simplifie la tâche d'écrire d’un compilateur et il compile généralement plus rapidement qu’un compilateur multi passe. Ainsi, alimentée en partie par des ressources limitées des premiers systèmes, de nombreux langages ont été spécifiquement conçus afin qu'ils puissent être compilés en un seul passage (par exemple, le langage Pascal).
Dans certains cas, la conception d'une fonctionnalité de langage a besoin d'un compilateur pour effectuer plus d'une passe sur la source. Par exemple, considérons une déclaration figurant à la ligne 20 de la source qui affecte la traduction d'une déclaration figurant à la ligne 10. Dans ce cas, la première passe doit recueillir des renseignements sur les déclarations figurant après les déclarations qu'ils affectent, avec la traduction proprement dite qui s’effectue lors d'un passage ultérieur.
L'inconvénient de la compilation en un seul passage, c'est qu'il n'est pas possible d'exécuter la plupart des optimisations sophistiquées nécessaires pour générer du code de haute qualité. Il peut être difficile de dénombrer exactement le nombre de passes qu’un compilateur optimisant effectue.
Le fractionnement d'un compilateur en petits programmes est une technique utilisée par les chercheurs intéressés à produire des compilateurs performants. Prouver la justesse d'une série de petits programmes nécessite souvent moins d'effort que de prouver la justesse d'un plus grand programme unique équivalent.
Les qualités d'un compilateur
La qualité la plus importante est bien sûr d'obtenir le « zéro bug », c'est donc la confiance. Ensuite, il y a le fait que le code généré doit être rapide : c'est l'optimalité. Le compilateur lui-même doit être rapide : l'efficacité. Le compilateur doit être compatible sur plusieurs plateformes : la portabilité. Les erreurs signalées doivent être utilisées : la productivité.
Le problème de l'amorçage (bootstrap)
Les premiers compilateurs étaient écrits directement en langage assembleur, un langage symbolique élémentaire correspondant aux instructions du processeur cible et quelques structures de contrôle légèrement plus évoluées. Ce langage symbolique doit être assemblé (et non compilé) et lié pour obtenir une version exécutable. En raison de sa simplicité, un programme simple suffit à le convertir en instructions machines.
Les compilateurs actuels sont généralement écrits dans le langage qu'ils doivent compiler ; par exemple un compilateur C est écrit en C, SmallTalk en SmallTalk, Lisp en Lisp, etc. Dans la réalisation d'un compilateur, une étape décisive est franchie lorsque le compilateur pour le langage X est suffisamment complet pour se compiler lui-même : il ne dépend alors plus d'un autre langage (fut-ce de l'assembleur) pour être produit.
Les bugs des compilateurs sont parfois très complexes à détecter. Si un compilateur de langage C comporte un bug, les programmeurs en langage C auront naturellement tendance à mettre en cause leur propre code source, non pas le compilateur.
Pire, si ce compilateur buggé (version V1) compile un compilateur (version V2) non buggé, l'exécutable compilé (par V1) du compilateur V2 sera buggé. Pourtant son code source est bon. Le bootstrap oblige donc les programmeurs de compilateurs à contourner les bugs des compilateurs existants.

















































