Chaîne de Markov - Définition
La liste des auteurs de cet article est disponible ici.
Classification des états

Pour ![]() , on dit que
, on dit que ![]() est accessible à partir de
est accessible à partir de ![]() si et seulement s'il existe
si et seulement s'il existe ![]() tel que
tel que  On note :
On note :
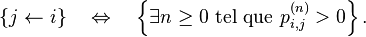
On dit que ![]() et
et ![]() communiquent si et seulement s'il existe
communiquent si et seulement s'il existe ![]() tels que
tels que  et
et  On note :
On note :
La relation communiquer, notée ![]() est une relation d'équivalence. Quand on parle de classe en parlant des états d'une chaîne de Markov, c'est général aux classes d'équivalence pour la relation
est une relation d'équivalence. Quand on parle de classe en parlant des états d'une chaîne de Markov, c'est général aux classes d'équivalence pour la relation ![]() qu'on fait référence. Si tous les états communiquent, la chaîne de Markov est dite irréductible.
qu'on fait référence. Si tous les états communiquent, la chaîne de Markov est dite irréductible.
La relation être accessible, notée ![]() s'étend aux classes d'équivalence : pour deux classes
s'étend aux classes d'équivalence : pour deux classes ![]() et
et ![]() , on a
, on a
La relation ![]() est une relation d'ordre entre les classes d'équivalence.
est une relation d'ordre entre les classes d'équivalence.
Une classe est dite finale si elle ne conduit à aucune autre, i.e. si la classe est minimale pour la relation ![]() Sinon, elle est dite transitoire. L'appartenance à une classe finale ou transitoire a des conséquences sur les propriétés probabilistes d'un état de la chaîne de Markov, en particulier sur son statut d'état récurrent ou d'état transient. Le nombre et la nature des classes finales dicte la structure de l'ensemble des probabilités stationnaires, qui résument de manière précise le comportement asymptotique de la chaîne de Markov, comme on peut le voir à la prochaine section et dans les deux exemples détaillés à la fin de cette page.
Sinon, elle est dite transitoire. L'appartenance à une classe finale ou transitoire a des conséquences sur les propriétés probabilistes d'un état de la chaîne de Markov, en particulier sur son statut d'état récurrent ou d'état transient. Le nombre et la nature des classes finales dicte la structure de l'ensemble des probabilités stationnaires, qui résument de manière précise le comportement asymptotique de la chaîne de Markov, comme on peut le voir à la prochaine section et dans les deux exemples détaillés à la fin de cette page.
Soit

La période d'un état ![]() est le PGCD de l'ensemble
est le PGCD de l'ensemble ![]() Si deux états communiquent, ils ont la même période : on peut donc parler de la période d'une classe d'états. Si la période vaut 1, la classe est dite apériodique. L'apériodicité des états d'une chaîne de Markov conditionne la convergence de la loi de
Si deux états communiquent, ils ont la même période : on peut donc parler de la période d'une classe d'états. Si la période vaut 1, la classe est dite apériodique. L'apériodicité des états d'une chaîne de Markov conditionne la convergence de la loi de ![]() vers la probabilité stationnaire, voir la page Probabilité stationnaire d'une chaîne de Markov.
vers la probabilité stationnaire, voir la page Probabilité stationnaire d'une chaîne de Markov.
La classification des états et leur période se lisent de manière simple sur le graphe de la chaîne de Markov. Toutefois, si tous les éléments de la matrice de transition sont strictement positifs, la chaîne de Markov est irréductible et apériodique : dessiner le graphe de la chaîne de Markov est alors superflu.
Probabilités de transition
Définition
Définition — Le nombre ![]() est appelé probabilité de transition de l'état
est appelé probabilité de transition de l'état ![]() à l'état
à l'état ![]() en un pas, ou bien probabilité de transition de l'état
en un pas, ou bien probabilité de transition de l'état ![]() à l'état
à l'état ![]() s'il n'y a pas d'ambiguité. On note souvent ce nombre
s'il n'y a pas d'ambiguité. On note souvent ce nombre ![]()
- La famille de nombres
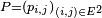 est appelée matrice de transition, noyau de transition, ou opérateur de transition de la chaîne de Markov.
est appelée matrice de transition, noyau de transition, ou opérateur de transition de la chaîne de Markov.
La terminologie matrice de transition est la plus utilisée, mais elle n'est appropriée, en toute rigueur, que lorsque, pour un entier ![]()
![]() Lorsque
Lorsque ![]() est fini, par exemple de cardinal
est fini, par exemple de cardinal ![]() on peut toujours numéroter les éléments de
on peut toujours numéroter les éléments de ![]() arbitrairement de 1 à
arbitrairement de 1 à ![]() ce qui règle le problème, mais imparfaitement, car cette renumérotation est contre-intuitive dans beaucoup d'exemples.
ce qui règle le problème, mais imparfaitement, car cette renumérotation est contre-intuitive dans beaucoup d'exemples.
Deux chiens se partagent ![]() puces de la manière suivante : à chaque instant, une des
puces de la manière suivante : à chaque instant, une des ![]() puces est choisie au hasard et saute alors d'un chien à l'autre. L'état du système est décrit par un élément
puces est choisie au hasard et saute alors d'un chien à l'autre. L'état du système est décrit par un élément ![]() où
où
Alors ![]() possède
possède ![]() éléments, mais les numéroter de 1 à
éléments, mais les numéroter de 1 à ![]() serait malcommode pour suivre l'évolution du système, qui consiste à choisir une des
serait malcommode pour suivre l'évolution du système, qui consiste à choisir une des ![]() coordonnées de
coordonnées de ![]() au hasard et à changer sa valeur. Si l'on veut comprendre le système moins en détail (car on n'est pas capable de reconnaître une puce d'une autre), on peut se contenter d'étudier le nombre de puces sur le chien n°1, ce qui revient à choisir
au hasard et à changer sa valeur. Si l'on veut comprendre le système moins en détail (car on n'est pas capable de reconnaître une puce d'une autre), on peut se contenter d'étudier le nombre de puces sur le chien n°1, ce qui revient à choisir ![]() Là encore, pour la compréhension, il serait dommage de renuméroter les états de 1 à
Là encore, pour la compréhension, il serait dommage de renuméroter les états de 1 à ![]() Notons que pour cette nouvelle modélisation,
Notons que pour cette nouvelle modélisation,
puisque, par exemple, le nombre de puces sur le dos du chien n°1 passe de k à k-1 si c'est une de ces k puces qui est choisie pour sauter, parmi les N puces présentes dans le "système". Ce modèle porte plus souvent le nom de "modèle des urnes d'Ehrenfest". Il a été introduit en 1907 par Tatiana et Paul Ehrenfest pour illustrer certains des « paradoxes » apparus dans les fondements de la mécanique statistique naissante, et pour modéliser le bruit rose. Le modèle des urnes d'Ehrenfest était considéré par le mathématicien Mark Kac [1] comme « ... probablement l'un des modèles les plus instructifs de toute la physique ... »
Plutôt que de renuméroter les états à partir de 1, il est donc plus ergonomique dans beaucoup de cas d'accepter des matrices finies ou infinies dont les lignes et colonnes sont "numérotées" à l'aide des éléments de ![]() Le produit de deux telles "matrices",
Le produit de deux telles "matrices", ![]() et
et ![]() , est alors défini très naturellement par
, est alors défini très naturellement par
par analogie avec la formule plus classique du produit de deux matrices carrées de taille ![]()
Propriétés
Proposition — La matrice de transition ![]() est stochastique : la somme des termes de n'importe quelle ligne de
est stochastique : la somme des termes de n'importe quelle ligne de ![]() donne toujours 1.
donne toujours 1.
Proposition — La loi de la chaîne de Markov ![]() est caractérisée par le couple constitué de sa matrice de transition
est caractérisée par le couple constitué de sa matrice de transition ![]() et de sa loi initiale (la loi de
et de sa loi initiale (la loi de ![]() ) : pour tout
) : pour tout ![]() la loi jointe de
la loi jointe de ![]() est donnée par
est donnée par
Par récurrence, au rang 0,
Au rang ![]() en posant
en posant ![]()
en vertu de la propriété de Markov faible, donc si ![]() a l'expression attendue, alors
a l'expression attendue, alors ![]() aussi.
aussi.
Lorsqu'on étudie une chaîne de Markov particulière, sa matrice de transition est en général bien définie et fixée tout au long de l'étude, mais la loi initiale peut changer lors de l'étude et les notations doivent refléter la loi initiale considérée sur le moment : si à un moment de l'étude on considère une chaîne de Markov de loi initiale définie par ![]() alors les probabilités sont notées
alors les probabilités sont notées ![]() et les espérances sont notées
et les espérances sont notées ![]() En particulier, si
En particulier, si ![]() on dit que la chaîne de Markov part de
on dit que la chaîne de Markov part de ![]() les probabilités sont notées
les probabilités sont notées ![]() et les espérances sont notées
et les espérances sont notées ![]()
Puissances de la matrice de transition
Pour ![]() la probabilité de transition en
la probabilité de transition en ![]() pas,
pas, ![]() ne dépend pas de
ne dépend pas de ![]() :
:
Proposition — La matrice de transition en ![]() pas,
pas, ![]() est égale à la puissance
est égale à la puissance ![]() -ème de la matrice de transition
-ème de la matrice de transition ![]() On note
On note
et
Par récurrence. Au rang 1, c'est une conséquence de l'homogénéité de la chaîne de Markov déjà mentionnée à la section :
Au rang ![]()
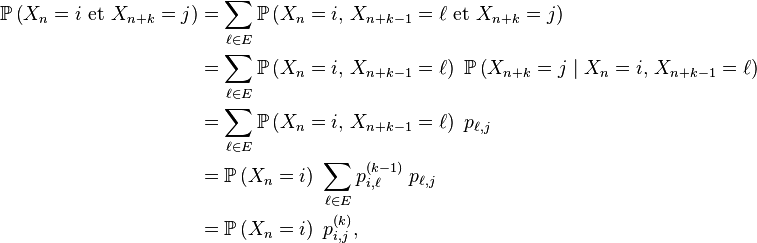
où
- la 1-ère égalité est le troisième axiome des probabilités,
- la 2-ème égalité est la définition d'une probabilité conditionnelle,
- la 3-ème égalité est due à une forme de propriété de Markov faible,
- la 4-ème égalité est la propriété de récurrence au pas
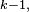
- la 5-ème égalité est la formule du produit de deux "matrices", appliquée au produit de
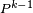 avec
avec 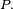
Pour conclure, on divise les deux termes extrêmes de cette suite d'égalités par ![]() sauf si ce dernier terme est nul, auquel cas on peut définir
sauf si ce dernier terme est nul, auquel cas on peut définir ![]() arbitrairement, donc, par exemple, égal à
arbitrairement, donc, par exemple, égal à ![]()
Par une simple application de la formule des probabilités totales, on en déduit les lois marginales de la chaîne de Markov.
Corollaire — La loi de ![]() est donnée par
est donnée par
En particulier,
En écriture matricielle, si la loi de ![]() est considérée comme un vecteur-ligne
est considérée comme un vecteur-ligne ![]() avec
avec ![]() cela se reformule en :
cela se reformule en :