Analyse de la variance - Définition
La liste des auteurs de cet article est disponible ici.
Analyse de la variance à deux facteurs
Également appelé two-way ANOVA (en), l'analyse de la variance à deux facteurs s'applique lorsque l'on souhaite prendre en compte deux facteurs de variabilité.
Décomposition de la variance
Soit un premier facteur de variabilité pouvant prendre les niveaux i = 1..p, un second facteur de variabilité pouvant prendre les niveaux j = 1..q, nij le nombre d'individu dans le niveau i du premier facteur et le niveau j du second facteur, n le nombre d'individu total et r le nombre d'individu dans chaque sous-groupe (pour un niveau i et un niveau j donné). La variable à expliquer s'écrit yijk avec i = 1..p, j = 1..ni et k = 1..mj.
La variable à expliquer peut être modélisée par la relation :

avec αi l'effet du niveau i du premier facteur, βj l'effet du niveau j du second facteur, γij l'effet d'interaction entre les deux facteurs et εijk l'erreur aléatoire (qui suit alors une loi normale

Le calcul présenté dans le cas à un facteur peut être transposé au cas à deux facteurs :

La part de la variance totale expliquée par le premier facteur (SCEfacteur 1), la part de la variance totale expliquée par le second facteur (SCEfacteur 2), l'interaction entre les deux facteurs (SCEinteraction) et la part de la variance totale qui ne peut être expliquée par le modèle (SCEresidu, appelé aussi variabilité aléatoire ou bruit) sont données par les formules :

| 
|

| 
|
L'analyse de l'interaction entre facteurs est relativement complexe. Dans le cas où les facteurs sont indépendants, on peut s'intéresser qu'aux effet principaux des facteurs. La formule devient alors :

Exemple illustratif
Notre exploitant laitier souhaite améliorer la puissance de son analyse en augmentant la taille de son étude. Pour cela, il inclut les données provenant d'une autre exploitation. Les chiffres qui lui sont fournit sont les suivant :
- Pour la race A : 22,8 ; 21,7 ; 23,3 ; 23,1 ; 24,1 ; 22,3 et 22,7
- Pour la race B : 23,1 ; 22,9 ; 21,9 ; 23,4 et 23,0
- Pour la race C : 31,7 ; 33,1 ; 32,5 ; 35,1 ; 32,2 et 32,6
Analyse réalisée avec R :
> produc ← c(20.1, 19.8, 21.3, 20.7, 22.6, 24.1, 23.8, 22.5, 23.4, 24.5, 22.9, 31.2, 31.6, 31.0, 32.1, 31.4, 22.8, 21.7, 23.3, 23.1, 24.1, 22.3, 22.7, 23.1, 22.9, 21.9, 23.4, 23.0, 31.7, 33.1, 32.5, 35.1, 32.2, 32.6) > race ← as.factor(c("A", "A", "A", "A", "B", "B", "B", "B", "B", "B", "B", "C", "C", "C", "C", "C", "A", "A", "A", "A", "A", "A", "A", "B", "B", "B", "B", "B", "C", "C", "C", "C", "C", "C")) > centre ← as.factor(c(rep("premier", 16), rep("second", 18))) > anova(lm(produc~race*centre)) Analysis of variance Table Response: produc Df Sum Sq Mean Sq F value Pr(>F) race 2 696.48 348.24 559.6811 < 2.2e-16 *** centre 1 8.46 8.46 13.6012 0.0009636 *** race:centre 2 12.23 6.11 9.8267 0.0005847 *** Residuals 28 17.42 0.62 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Analyse de la variance à un facteur
Également appelé one-way ANOVA (en), l'analyse de la variance à un facteur s'applique lorsque l'on souhaite prendre en compte un seul facteur de variabilité.
- Notation
Considérons I échantillons Yi d'effectifs ni, issu des I populations qui suivent I lois normales

![i \in [1, I]](https://static.techno-science.net/illustrationWebp/Definitions/autres/e/e82f7108e7c2a5c900ea5d4c97ab3c58_5f959cb716e011045d014fb554db39a0.png)
![j \in [1, n_i]](https://static.techno-science.net/illustrationWebp/Definitions/autres/f/f9e3629ba70aea17b424e5c3850c94dc_397fe194b6fad6d62ddcaf59d1820aee.png)
Les moyennes par échantillon et totale s'écrivent :


Décomposition de la variance
Le modèle s'écrit :

Dans ces conditions, on montre que la somme des carrés des écarts (et donc la variance) peut être calculée simplement par la formule :

La part de la variance totale SCEtotal qui peut être expliquée par le modèle (SCEfacteur, aussi appelée variabilité inter-classe, SSB ou Sum of Square Between class) et la part de la variance totale SCEtotal qui ne peut être expliquée par le modèle (SCEresidu aussi appelée variabilité aléatoire, variabilité intra-classe, bruit, SSW ou Sum of Square Within class) sont données par les formules :


-
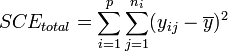
- En décomposant
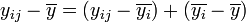
- on peut écrire
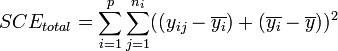
-
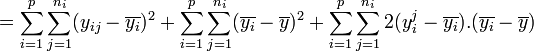
- En remarquant que
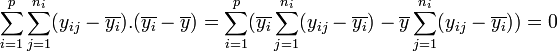
- on peut écrire
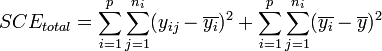
-
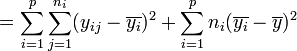
-
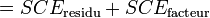








Analyse des résidus
Il est toujours possible que le modèle ne soit pas correct et qu'il existe un facteur de variabilité inconnu (ou supposé a priori inutile) qui ne soit pas intégré dans le modèle. Il est possible d'analyser la normalité de la distribution des résidus pour rechercher ce type de biais. Les résidus, dans le modèle, doivent suivre une loi normale

- layout(matrix(1:3, 1, 3))
- produc ← c(20.1, 19.8, 21.3, 20.7, 22.6, 24.1, 23.8, 22.5, 23.4, 24.5, 22.9, 31.2, 31.6, 31.0, 32.1, 31.4, 22.8, 21.7, 23.3, 23.1, 24.1, 22.3, 22.7, 23.1, 22.9, 21.9, 23.4, 23.0, 31.7, 33.1, 32.5, 35.1, 32.2, 32.6)
- race ← as.factor(c("A", "A", "A", "A", "B", "B", "B", "B", "B", "B", "B", "C", "C", "C", "C", "C", "A", "A", "A", "A", "A", "A", "A", "B", "B", "B", "B", "B", "C", "C", "C", "C", "C", "C"))
- plot(residuals(lm(produc~race)), ylab="Residus", col="blue")
- abline(0, 0, col="red")
- hist(residuals(lm(produc~race)), nclass=20, xlab="Residus", ylab="Frequence", xlim=c(-3,3), pro=T, col="blue", main="Analyse des residus")
- lines(seq(-3,3,le=100), dnorm(seq(-3,3,le=100), 0, sqrt(var(residuals(lm(produc~race))))), col="red")
- qqnorm(residuals(lm(produc~race)))
- qqline(residuals(lm(produc~race)), col="red")
Test de Fisher
- Degrés de liberté et variances
Par hypothèse, la variable observée yi suit une loi normale. La loi du χ² à k degrés de liberté étant définit comme étant la somme de k lois normales au carré, les sommes des carrés des écarts SCE suivent les lois du χ² suivantes, avec p le nombre de niveaux du facteur de variabilité et n le nombre total d'individu :


Les variances s'obtiennent en faisant le rapport de la somme des carrés des écarts sur le nombre de degrés de liberté :


La Loi de Fisher étant défini comme le rapport de deux lois du χ², le rapport


- Remarque
Pour les amateurs de géométrie vectorielle, la décomposition des degrés de liberté correspond à la décomposition d'un espace vectoriel de dimension nm en sous espaces supplémentaires et orthogonaux de dimensions respectives m − 1 et m(n − 1). Voir par exemple le cours dispensé par Toulouse III : [1] pages 8 et 9. On peut se reporter aussi au livre classique de Scheffé (1959)
- Test d'adéquation à la loi de Fisher

Il se trouve (comme on peut le voir dans la décomposition mathématique) que les deux termes sont tous les deux une estimation de la variabilité résiduelle si le facteur A n'a pas d'effet. De plus, ces deux termes suivent chacun une loi de χ², leur rapport suit donc une loi de F (voir plus loin pour les degrés de liberté de ces lois). Résumons :
- Si le facteur A n'a pas d'effet, le rapport de Sa et Sr suit une loi de F et il est possible de vérifier si la valeur du rapport est « étonnante » pour une loi de F
- Si le facteur A a un effet, le terme Sa n'est plus une estimation de la variabilité résiduelle et le rapport
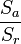
Résumer les choses ainsi permet de clarifier l'idée mais renverse la démarche : on obtient en pratique une valeur du rapport

CMB est l'estimateur SA présenté au paragraphe précédent (première approche technique) et CMW l'estimateur SB. On en déduit le F de Fisher, dont la distribution est connue et tabulée sous les hypothèses suivantes :
- Les résidus ε sont distribués normalement
- Avec une espérance nulle
- Avec une variance σ2 indépendante de la catégorie i
- Avec une covariance nulle deux à deux (indépendance)
Le respect de ces hypothèses assure la validité du test d'analyse de la variance. On les vérifie a posteriori par diverses méthodes (tests de normalité, examen visuel de l'histogramme des résidus, examen du graphique des résidus en fonction des estimées) voir condition d'utilisation ci-dessous.
Table d'ANOVA
La table d'ANOVA permet de résumer les calculs nécessaires :
| Source de la variance | Sommes des carrés des écarts | Degrés de liberté | Variance | F | p-value |
|---|---|---|---|---|---|
| Inter-classes | SCEfacteur | DDLfacteur |

|

|  |
| Intra-classe | SCEresidu | DDLresidu |

| ||
| Total | SCEtotal | DDLtotal |
Exemple illustratif
Prenons un exemple pour illustrer la méthode. Imaginons un éleveur qui souhaite acheter de nouvelles vaches pour sa production laitière. Il possède trois races différentes de vaches et se pose donc la question de savoir si la race est importante pour son choix. Il possède comme informations la race de chacune de ses bêtes (c'est la variable explicative discrète ou facteur de variabilité, qui peut prendre 3 valeurs différentes) et leurs productions de lait journalières (c'est la variable à expliquer continue, qui correspond au volume de lait en litre).
Dans notre exemple, l'hypothèse nulle revient à considérer que toutes les vaches produisent la même quantité de lait journalière (au facteur aléatoire près) quelle que soit la race. L'hypothèse alternative revient à considérer qu'une des races produit significativement plus ou moins de lait que les autres.
Supposons que les productions sont :
- Pour la race A : 20,1 ; 19,8 ; 21,3 et 20,7
- Pour la race B : 22,6 ; 24,1 ; 23,8 ; 22,5 ; 23,4 ; 24,5 et 22,9
- Pour la race C : 31,2 ; 31,6 ; 31,0 ; 32,1 et 31,4
| Race | Taille | Moyenne | Variance |
|---|---|---|---|
| A | 4 | 20,475 | 0,4425 |
| B | 7 | 23,4 | 0,59333 |
| C | 5 | 31,46 | 0,178 |
| Total | 16 | 25,1875 | 20,90117 |
- Table d'ANOVA
| Source de la variance | Sommes des carrés des écarts | Degrés de liberté | Variance | F | p-value |
|---|---|---|---|---|---|
| Inter-classes | 307,918 | 2 | 153,959 | 357,44 | 4,338e-12 |
| Intra-classe | 5,6 | 13 | 0,431 | ||
| Total | 313.518 | 15 |
- Analyse réalisée avec R
> produc ← c(20.1, 19.8, 21.3, 20.7, 22.6, 24.1, 23.8, 22.5, 23.4, 24.5, 22.9, 31.2, 31.6, 31.0, 32.1, 31.4) > race ← as.factor(c("A", "A", "A", "A", "B", "B", "B", "B", "B", "B", "B", "C", "C", "C", "C", "C")) # Regardons les moyennes par groupe: > tapply(produc, race, mean) A B C 20.475 23.400 31.460 # On remarque des différences entre groupes, mais sont-elles statistiquement significatives? # Testons le par l'ANOVA: > anova(lm(produc~race)) Analysis of variance Table Response: produc Df Sum Sq Mean Sq F value Pr(>F) race 2 307.918 153.959 357.44 4.338e-12 *** Residuals 13 5.600 0.431 Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Les résultats de l'analyse sont présentés dans un tableau (les couleurs ont été ajoutées pour faciliter l'explication). Le tableau contient 3 lignes : la première contient les titres des colonnes, la dernière contient l'analyse des résidus. Le tableau contient également une ligne par facteur de variabilité (une seule dans cet exemple).
- La première colonne (en rouge) indique les facteurs analysés : le facteur "race" et les résidus ("Residuals" (en)).
- La seconde colonne (en bleu) indique le nombre de degrés de liberté : 3 races différentes - 1 = 2 degrés de libertés pour le facteur "race" ; 16 individus dans l'étude - 3 niveaux pour le facteur "race" = 13 degrés de liberté pour les résidus.
- La cinquième colonne (en vert) indique le F calculé dans cet exemple.
- La sixième colonne (en marron) indique la probabilité que l'hypothèse nulle soit vraie (p-value). Dans cet exemple, la valeur très basse indique que l'on peut rejeter l'hypothèse nulle avec très peu de risque : l'agriculteur peut conclure "les 3 races de vaches ne produisent pas la même quantité journalière de lait". Le nombre d'étoiles à côté de la valeur de p indique la confiance que l'on peut accorder au résultat : 3 étoiles indiquent que le résultat est très sûr (p-value < 0,001).

















































