Distribution de Pareto - Définition
Densité de probabilité / Fonction de masse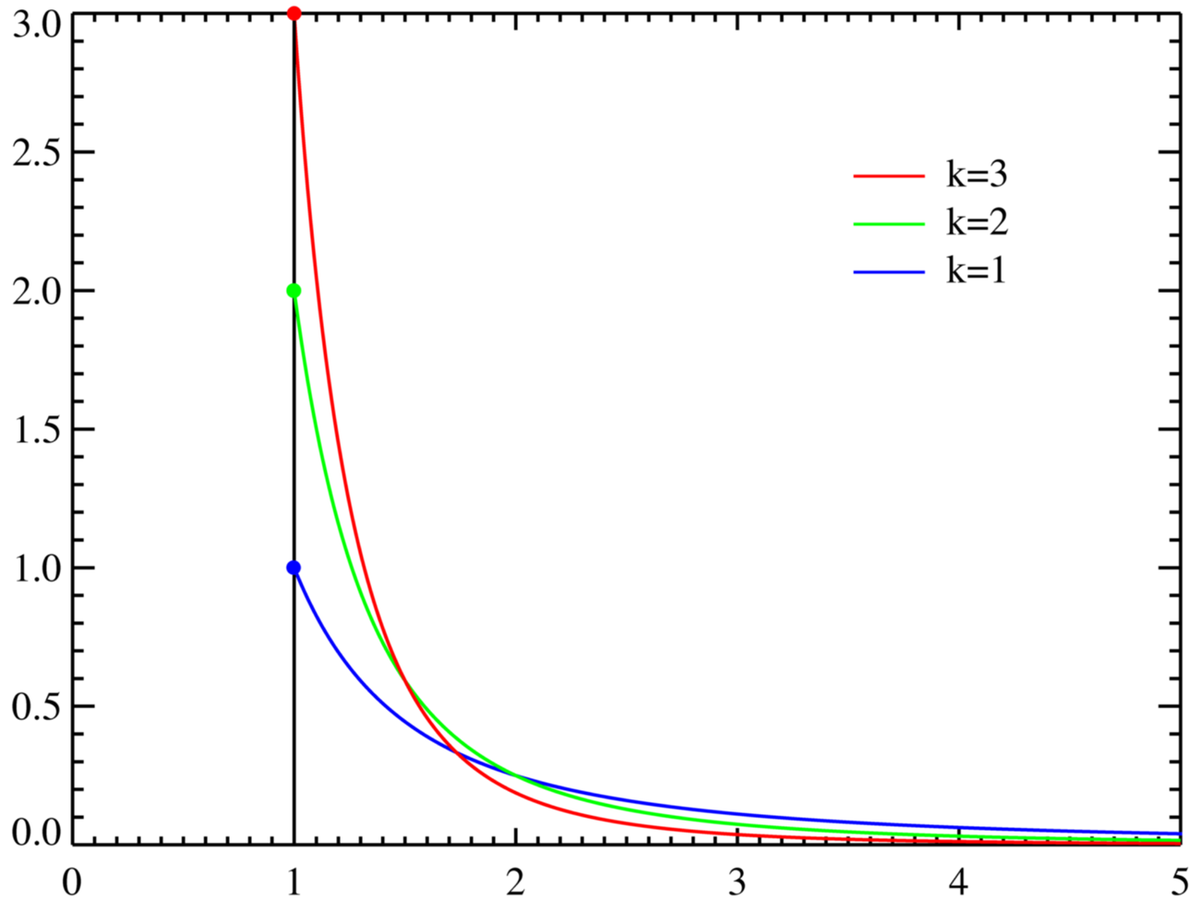
Fonctions de masse pour plusieurs k avec xm = 1. L'axe horizontal symbolise le paramètre x . Lorsque k->∞ la distribution s'approche de δ(x − xm) où δ est fonction Delta de Dirac. |
|
Fonction de répartition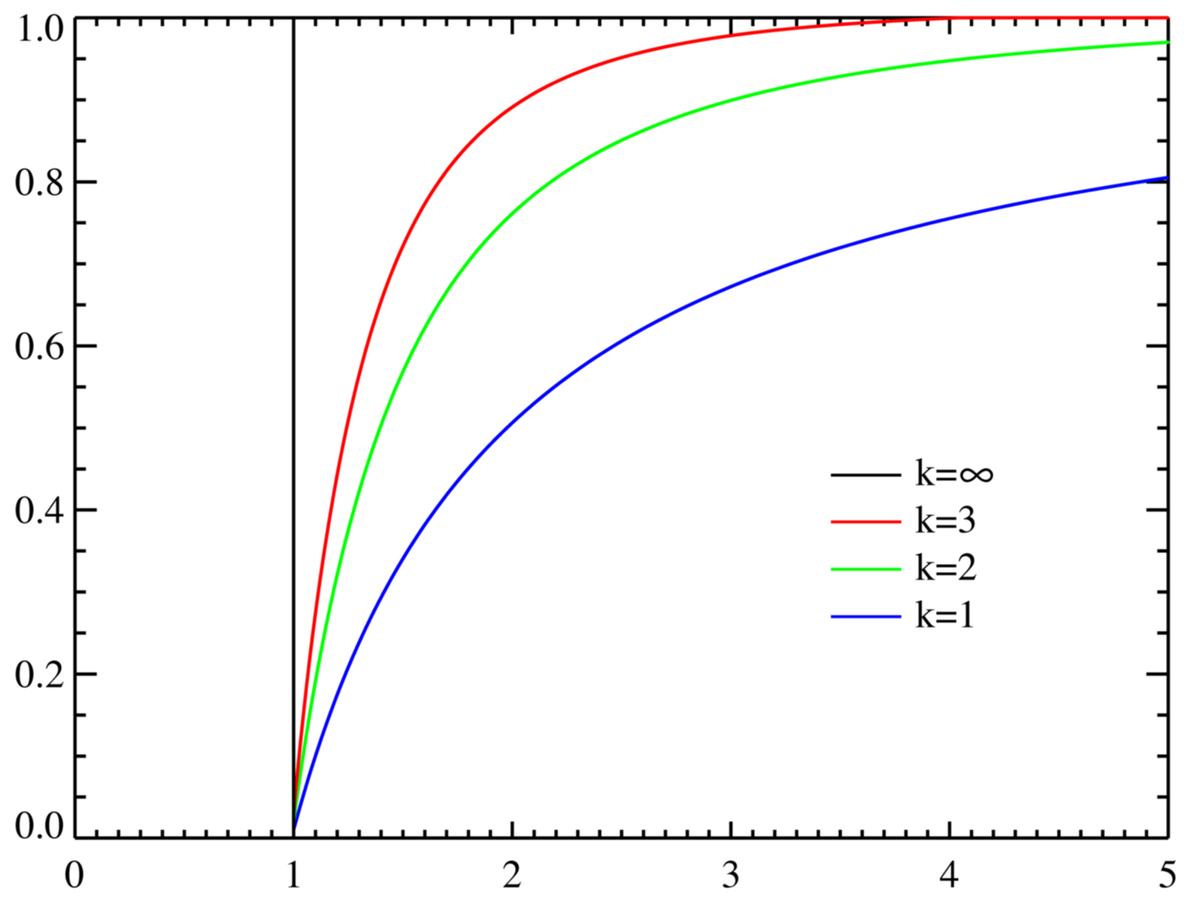
Fonctions de répartition pour plusieurs k avec xm = 1. L'axe horizontal symbolise le paramètre x |
|
| Paramètres | xm > 0 location (réel) k > 0 forme (réel) |
| Support |

|
| Densité de probabilité (fonction de masse) |

|
| Fonction de répartition |

|
| Espérance |

|
| Médiane (centre) |
![x_m \sqrt[k]{2}](https://static.techno-science.net/illustrationWebp/Definitions/autres/a/adc80b04fbec50f6e13a55411bad3332_9ac9eab5ead40522601c7fa689e0897b.png)
|
| Mode | xm |
| Variance |

|
| Asymétrie (skewness) |

|
| Kurtosis (non-normalisé) |

|
| Entropie |

|
| Fonction génératrice des moments | non définie |
| Fonction caractéristique | k( − ixmt)kΓ( − k, − ixmt) |
La distribution de Pareto est la formalisation de la loi de Pareto, aussi appelée principe des 80-20, courbe A-B-C.
Cet outil d'aide à la décision détermine les facteurs (environ 20%) cruciaux qui influencent la plus grande partie (80%) de l'objectif.
Historique
L'économiste italien Vilfredo Federigo Damaso Pareto (1848-1923) observa au début du XXe siècle que 20% de la population italienne possédait 80% de la richesse nationale d'où le nom de la loi 80-20 ou 20-80.
Cette observation fut généralisée plus tard par Joseph Juran.
Formalisme
Soit la variable aléatoire X qui suit une loi de Pareto de paramètres (xmin,k), alors la distribution est caractérisée par :


Applications
Cette loi est un outil fondamental en gestion de la qualité. Elle est aussi utilisée en réassurance. La théorie des files d'attente s'est intéressée à cette distribution, lorsque des recherches des années 90 ont montré que cette loi régissait aussi nombre de grandeurs observées dans le trafic Internet (et plus généralement sur tous les réseaux de données à grande vitesse). Ce phénomène a de sévères répercussions sur les performances des systèmes (routeurs en particulier).
Exemples
- Fiscalité : 20% des citoyens imposables génèrent 80% de la trésorerie publique.
- Sport : 20 % de l'effort à l'entraînement permet d'atteindre 80% de la performance.
- Service après vente : 80% des réclamations proviennent de 20% des clients
- Contrôle de gestion : 20% des indicateurs fournissent 80% de l'information. Souvent contraint à une décision rapide, le manager préférera une information partielle au bon moment, plutôt qu'une information complète qui arriverait trop tard. Ce constat retiendra l'attention des concepteurs de tableaux de bord, où l'on peut recommander de n'intégrer que des indicateurs pertinents, c'est-à-dire non seulement à même de confirmer que l'entreprise est en bonne voie vers l'atteinte des objectifs fixés, mais également rapidement disponibles (ne pas négliger le coût d'obtention d'une information). Toutefois, il faut garder à l'esprit que le manager est responsable de ses décisions et qu'il devra donc mesurer le risque lié à la relative imprécision de l'information dont il dispose.
- Trafic internet : la taille des fichiers échangés, la durée des sessions FTP ou HTTP et d'autres ont des distributions proches de celle de Pareto.
Distributions de probabilité
Les distributions de Pareto sont des distributions continues. La loi de Zipf, parfois nommée distribution zeta, peut être considérée comme l'équivalent discret de la loi de Pareto.
Soit une variable aléatoire X suivant une distribution de Pareto, alors la probabilité que X soit plus grande qu'un réel x est donnée par:
-
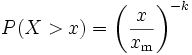

pour tout x ≥ xm, où xm est la valeur minimale (positive) que peut prendre X, etk est un réel positif.
Il suit que la densité de probabilité de X suit:

La distribution de Pareto est définie par deux paramètres, xm et k. Le paramètre k est souvent nommé indice de Pareto.
Moments
L' espérance d'une variable aléatoire suivant une loi de pareto est

(il est à noter que si k ≤ 1, l'espérance est infinie).
Sa variance est

(De nouveau,: si

Les moments d'ordre supérieur sont donnés par:

mais ils ne sont définis que pour k > n.
Cela signifie que la fonction génératrice (la série de Taylor en x où les μn' / n! sont pris pour coefficients) n'est pas définie. Cette propriété est vraie en général pour les variables aléatoires présentant le caractère 'heavy tail'.
La fonction caractéristique est donnée par:

où Γ(a,x) est la fonction gamma incomplète.
La distribution de Pareto est reliée à la distribution exponentielle par:

La fonction delta de Dirac est un cas limite de la distribution de Pareto:

Propriétés
La distribution de Pareto est Heavy tailed, ce qui signifie que:
-
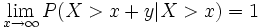

Par exemple, si X est le temps de vie d'un composant, plus il a vécu (X>x) plus il a de chances de vivre longtemps: le système rajeunit.
Estimation des paramètres
Fonction de vraissemblance: Maximum de vraissemblance: Estimation de l'indice: estimateur de Hill

















































