Reconnaissance de l'écriture manuscrite - Définition
La reconnaissance de l'écriture manuscrite est un traitement informatique qui a pour but de traduire un texte écrit en un texte codé numériquement.
Il faut distinguer deux reconnaissances distinctes, avec des problématiques et des solutions différentes :
- la reconnaissance en-ligne ;
- la reconnaissance hors-ligne.
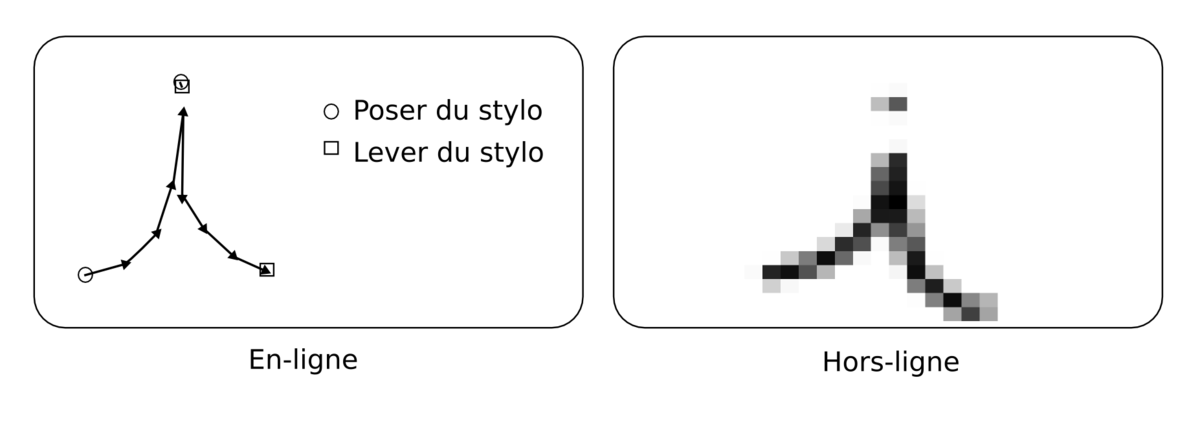
La reconnaissance de l'écriture manuscrite fait appel à la reconnaissance de forme, mais également au traitement automatique du langage naturel.
Reconnaissance hors-ligne
La reconnaissance hors-ligne travaille sur un instantané d'encre numérique (sur une image). C'est le cas notamment de la Reconnaissance Optique de l'Écriture. Dans ce contexte il est impossible de savoir comment ont été tracés les différents motifs ; il est seulement possible d'extraire des formes à partir de l'image, en s'appuyant sur les technologies de reconnaissance de forme.
C'est évidemment le type de reconnaissance privilégié pour les traitements asynchrones tels que la lecture de chèque bancaire ou le tri postal.
Reconnaissance en-ligne
Dans le cadre de la reconnaissance en-ligne, l'échantillon d'encre est constitué d'un ensemble de coordonnées ordonnées dans le temps. Il est ainsi possible de suivre le tracé, de connaître les posés et levés de stylo et éventuellement l'inclinaison et la vitesse. Il faut évidemment un matériel spécifique pour saisir un tel échantillon, c'est le cas notamment des stylos numériques ou des stylets sur agendas électroniques ou sur les Tablets PC.
La reconnaissance en-ligne est généralement beaucoup plus efficace que la reconnaissance hors-ligne car les échantillons sont beaucoup plus informatifs. En revanche, elle nécessite un matériel beaucoup plus coûteux et impose de fortes contraintes au scripteur puisque la capture de l'encre doit se faire au moment de la saisie (capture synchrone) et non a posteriori (capture asynchrone).
Les techniques usitées peuvent avoir un champ applicatif plus vaste permettant la reconnaissance de toute forme abstraite simple (cf. Reconnaissance de formes, Intelligence artificielle faible). Les systèmes actuels (2005) procèdent majoritairement par une comparaison de l'échantillon à reconnaître avec ceux contenus dans une base de données servant de comparatifs. Il est donc nécessaire au système de :
- soit posséder préalablement une base de données des formes reconnaissables ;
- soit passer par une phase de calibrage, c’est-à-dire, "d'apprentissage" des formes abstraites à reconnaître pour constituer cette base de données.
Les techniques de comparaison reposent généralement sur des méthodes statistiques simples pour gagner en vitesse de traitement. Ce qui induit que :
- plus le nombre de formes que le système peut reconnaître est grand,
- plus la précision statistique des comparaîsons doit l'être et, par conséquent,
- moins la qualité de la reconnaissance le sera.
Ceci car la qualité des systèmes de reconnaissances repose sur leur capacité a faire des choix fiables basés sur des approximations. Or, en matière d'écriture manuscrite, l'approximation est, de par le facteur humain, inéluctable : il est quasiment impossible qu'un utilisateur de ces systèmes reproduise une forme exactement telle qu'elle aura été préalablement mémorisée dans la base de données comparative ! En revanche, ces systèmes permettent de comparer et reconnaître facilement quelques formes simples, sans se soucier ni de la taille, ni de l'orientation, ni de l'exactitude "spaciale" de l'originale contenu dans la base de donnée comparative ! Cependant, les limitations intrinsèques restreignent les domaines applicatifs à des opérations de reconnaissance simples et rapides.
Citons pour exemple la technique qui semblerait demeurer la plus simple, la plus facile et la plus rapide à implémenter en programmation informatique. Il s'agit d'une comparaison de la moyenne de la somme des ségments reliants chaque points de la figure à son premier point. Ce mode de reconnaissance d'écriture induit que l'édition des figures soit vectorielle, donc, constituée de segments juxtaposés eux-même constitués/limités par des points. Autrement dit, une figure n'est qu'un ensemble de points reliés entre eux et ayant leurs coordonnées sur un plan en deux dimensions.
- On considère le premier point tracé comme étant le point de référence ; en quelque sorte, le centre de la figure autour duquel gravitent les autres points formant le nuage.
- Pour s'abstraire des contraintes de considération de l'orientation et de l'unicité formelle du contour de la figure (la forme physique exacte), on ne prend en considération que la taille des ségments/vecteurs reliant le point de référence à chacun des points satellites.
- Pour se faire, on utilise tout simplement le théorème de Pythagore.
- On réduit donc la définition de la figure à la somme de tous ces ségments, donc, à une longueur sur une seule dimension !
- Pour s'abstraire de la contrainte de l'échelle (liée au contexte physique) et d'autres contraintes (liées aux technologies d'acquisition utilisées), on procède à la moyenne de la longueur en la divisant par le nombre de points satellites.
- On obtient ainsi qu'une seule valeur à comparer avec celles mémorisées dans la base de données.
- La comparaison se devant d'être approximative, une tolérance doit être définit, soit par l'utilisateur, soit de manière automatique en fonction du nombre de figures que le système doit pouvoir reconnaître.
Reconnaissance de forme
La reconnaissance de forme joue un rôle très important dans la reconnaissance de l'écriture à deux niveaux :
- l'extraction de graphème, ou segmentation ;
- la reconnaissance de motif.
Extraction de graphème
La reconnaissance de forme s'applique sur un motif. Il faut donc en premier lieu séparer les différents motifs composant les mots (lettres, chiffres, symboles...) avant de les reconnaître.
Sur l'exemple suivant, les différents points de séparation possibles sont annotés.

Il est évident que toutes les segmentations ne sont pas correctes et que seules certaines doivent être conservées. Il existe donc une ambiguïté qu'il faut lever pour optimiser la reconnaissance.
Reconnaissance de motifs
À partir des graphèmes extraits précédemment, la reconnaissance de forme permet d'obtenir les différents motifs la composant. La reconnaissance de motifs va également assister l'extraction de graphèmes en écartant une partie des segmentations impossible. Ainsi, plus la reconnaissance de motif est efficace et plus la segmentation l'est. De la même façon, une segmentation efficace conduit nécessairement à une meilleure reconnaissance. Il faut segmenter pour reconnaître, et reconnaître pour segmenter.
Assistance du modèle de langage
Il reste beaucoup d'ambiguïtés après les opérations de segmentation et de reconnaissance. Le traitement du langage intervient à ce niveau en écartant les solutions les moins probables, d'un point de vue linguistique.
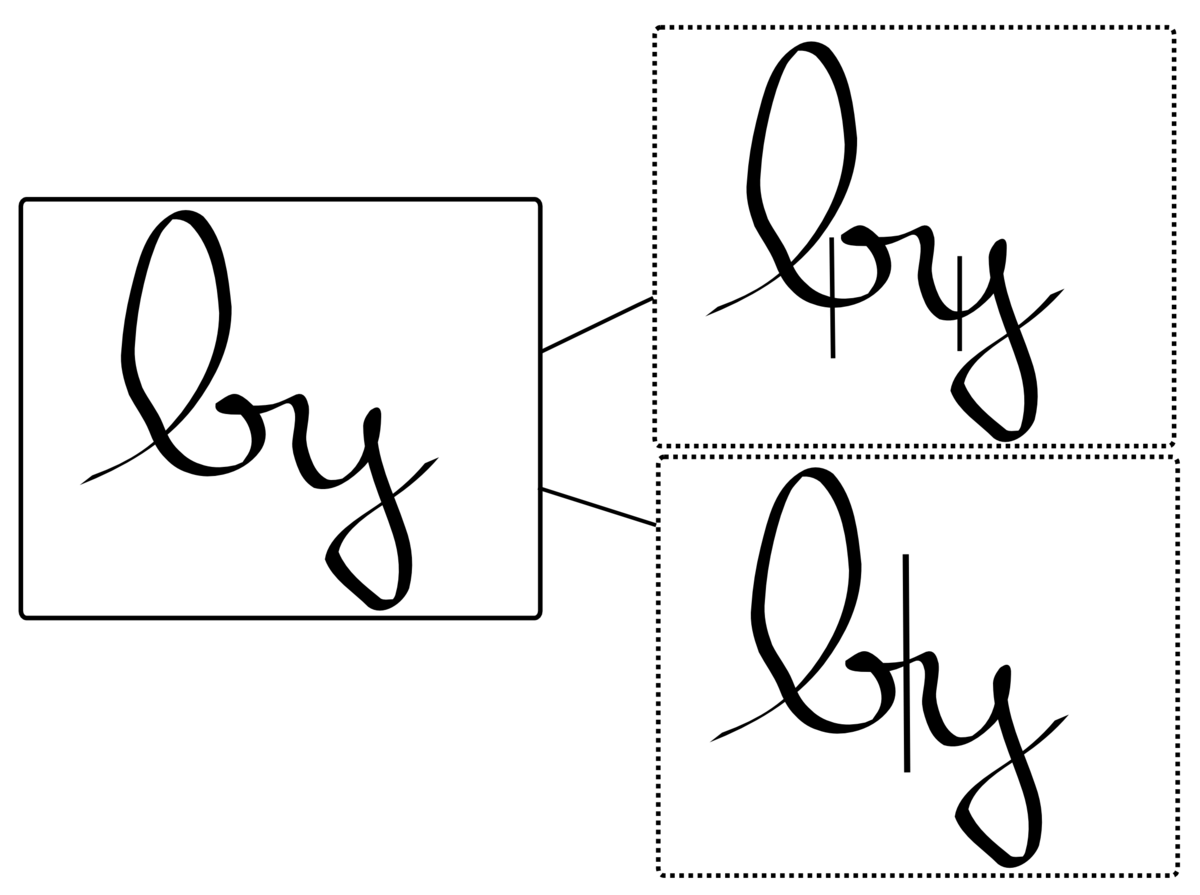
Dans l'exemple précédent, les étapes de segmentations et de reconnaissance de forme ont conduit aux choix "lrj" ou "by". Le modèle de langage (parfois un simple dictionnaire) choisira vraisemblablement la solution "by" en fonction de la langue. Le modèle de langage peut-être beaucoup plus complexe et reconnaître par exemple des suites de formes (n-grammes). Ainsi " Il est " sera préféré à " Il ont " en cas d'ambiguïté.
Collaboration des traitements
Le déroulement de la reconnaissance n'est pas linéaire : les différents traitements apportant à chaque fois un peu plus d'information sur les solutions probables, il peut être intéressant de reprendre une étape à partir des informations fournies par un traitement précédent pour affiner le résultat. Il y a ainsi une collaboration des différents traitements pour augmenter la fiabilité de la reconnaissance.
A priori sur le langage
Quel que soit le type de reconnaissance de l'écriture, l'affinage du modèle de langage est la clé de l'optimisation. En effet, pour garantir de bons résultats il faut plutôt voir le traitement comme faire un choix de solution(s) parmi un ensemble de choix proposé a priori plutôt que de chercher à deviner, à partir de la forme, ce que le scripteur a voulu écrire. Chercher à reconnaître un texte sans aucune information est à ce jour très difficile, alors que chercher à reconnaître le même texte si l'on connaît la langue employée et le registre (prise de note, texte " correct ", SMS) est beaucoup plus efficace.
De cette façon la technologie est suffisamment avancée pour permettre de reconnaître très rapidement et avec une excellente fiabilité l'adresse sur une enveloppe : le système ne cherche pas à reconnaître au hasard une information, mais à extraire un code postal (5 chiffres) parmi tous ceux qu'il connaît. Un nouveau tri par quartier est alors possible : le système cherchera à extraire la rue parmi celles qu'il connaît pour ce code postal.
À titre d'analogie, il est possible pour un être humain de comprendre l'intégralité d'une phrase même lorsqu'une partie est bruité, par exemple le lecteur parviendra sans aucun doute à comprendre la phrase bruité suivante : "je suis allé au ci*** voir un film", grâce au contexte posé par le reste de la phrase. Ce contexte donne un a priori sur le mot bruité à reconnaître.

















































