Restez toujours informé: suivez-nous sur Google Actualités (icone ☆)
ECAI est la conférence européenne de référence sur l'intelligence artificielle. L'opportunité de découvrir quelques aspects de ce vaste domaine de recherche. Dans ce premier focus, nous découvrons une avancée en compilation de réseaux bayésiens, des représentations informatiques aux multiples applications. Cette amélioration se traduit par une transformation du réseau bayésien en une formule logique pondérée.
Suscitant une littérature scientifique abondante depuis plus de quarante ans, les réseaux bayésiens constituent un des succès importants de l'intelligence artificielle, avec des applications dans de multiples domaines, tels que la biologie, la bioinformatique, la médecine, le traitement d'images, les réseaux sociaux et l'analyse financière.
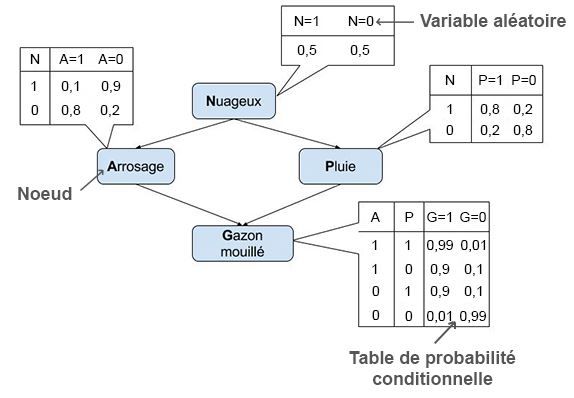
Les réseaux bayésiens sont des graphes orientés, c'est-à-dire des représentations à base de points (des noeuds) et de flèches (des arcs) les reliant. La figure d'exemple ci-dessus présente un réseau bayésien. Les noeuds d'un réseau bayésien représentent des variables aléatoires. Il y en a quatre sur l'exemple (Nuageux, Arrosage, Pluie et Gazon mouillé) et ces variables prennent ici des valeurs binaires (1 ou 0). Le graphe est orienté car les arcs ont une flèche, chaque arc exprime une influence directe de la variable d'origine sur la variable qui est à l'extrémité de la flèche. Ainsi, le fait que le temps soit nuageux a une influence sur le fait que l'arrosage automatique se déclenche ou pas. Sur l'exemple, Arrosage et Pluie sont les "parents" de Gazon mouillé.
La force des réseaux bayésiens est qu'ils permettent de représenter des distributions de probabilité de façon concise, c'est-à-dire sans avoir besoin de préciser explicitement la probabilité de chaque événement. Pour cela, chaque noeud est associé à une distribution de probabilité (donnée ici par une table) qui indique comment la probabilité qu'une variable prenne une certaine valeur dépend des valeurs prises par ses variables parents. Dans notre exemple, la table de probabilité conditionnelle associée à la variable Arrosage indique que la probabilité que l'arrosage se mette en route (A=1) quand le temps est nuageux (N=1) vaut 0,1.
Parmi les opérations fondamentales à réaliser à partir d'un réseau bayésien figurent le calcul de la probabilité d'un événement donné et le calcul d'une explication la plus probable: étant donné un événement, trouver une affectation de valeurs aux variables restantes, ayant une probabilité maximale. Sur l'exemple précédent, on pourrait vouloir calculer la probabilité que le gazon soit mouillé et que l'arrosage automatique ne se soit pas mis en route. Ayant observé que le temps n'est pas nuageux et que le gazon est mouillé, on pourrait aussi vouloir calculer la probabilité de l'explication la plus probable (L'arrosage s'est-il mis en route ? A-t-il plu ?). Toutefois, ces opérations sont, en général, difficiles à calculer.
Afin de pallier cette complexité calculatoire, une approche consiste à "compiler" l'information contenue dans le réseau bayésien en un circuit arithmétique. Pour cela, le réseau bayésien est d'abord traduit en une formule logique pondérée, les poids permettant de représenter les distributions conditionnelles du réseau. Cette formule logique est ensuite compilée en un circuit arithmétique, représentation compacte d'une expression arithmétique liant des nombres et des variables, et utilisant les opérations d'addition et de multiplication. La structure d'un circuit arithmétique permet ainsi de traiter beaucoup plus rapidement les opérations précédentes.
La contribution de l'article "An Improved CNF Encoding Scheme for Probabilistic Inference" d'Anicet Bart[1], Frédéric Koriche [2], Jean-Marie Lagniez [2] et Pierre Marquis [2], est une nouvelle méthode de transformation (prouvée correcte) d'un réseau bayésien en une formule logique, dans laquelle les variables (et leurs négations) ont des poids. En considérant (entre autres choses) un poids par table de façon implicite, les formules obtenues portent sur des nombres de variables plus petits et sont plus concises que celles obtenues en utilisant les méthodes de transformation qui existaient jusqu'ici. Expérimentalement, elles conduisent à des circuits arithmétiques dont les tailles sont souvent bien plus petites.
Notes:
[1] Laboratoire d'Informatique de Nantes Atlantique (LINA - CNRS/Université de Nantes/École des Mines de Nantes)
[2] Centre de Recherche en Informatique de Lens (CRIL - CNRS/Université de l'Artois)
Populaires